
Atualizado em 08/06/2026
Série Firecracker:
- Parte 01: Firecracker
- Parte 02: Construindo um nano-Lambda
- Parte 03: Redes no Firecracker
- Parte 04: Snapshots (você está aqui)
- Parte 05: Firecracker em produção
Nos artigos anteriores, construímos um nano-Lambda que gera QR codes e valida URLs. Funciona bem, roda em menos de 2 segundos. Mas e se a gente quisesse algo mais pesado? Um classificador de spam com machine learning, por exemplo?
Aí a coisa complica. Bibliotecas como scikit-learn demoram segundos só pra carregar. Cada execução do nano-Lambda vira uma espera de uns 9 segundos olhando pro terminal. Tenta ficar nove segundos olhando pra uma tela sem piscar. É uma eternidade. Se você rodar isso 10 vezes pra debugar, já perdeu mais de um minuto de vida olhando pro nada.
O problema é que a gente tá “ligando o computador” toda vez. Boot do kernel, init do sistema, import de bibliotecas pesadas… tudo do zero, a cada requisição. É como se você desligasse e ligasse seu notebook toda vez que quisesse abrir uma nova aba do Chrome.
A AWS não faz isso. Ela usa uma técnica chamada snapshot: tira uma “foto” da VM já pronta e restaura essa foto instantaneamente quando precisa. É hibernação turbinada. Você clona um computador que já está ligado, com todos os programas abertos, e ele acorda sem saber que foi copiado.
Hoje a gente implementa isso.
TL;DR: o que você vai conseguir
Métrica Antes Depois Tempo de inicialização ~9s ~300ms Speedup n/a ~30x Custo CPU (boot completo) Storage (512MB)
O problema: cold start pesado
Olha só onde o tempo tá indo. Quando a gente roda o classificador de spam com scikit-learn, dá pra ver exatamente o que tá demorando:
| Etapa | Tempo |
|---|---|
| Copiar o rootfs (512MB) | ~0.2s |
| Iniciar Firecracker + socket | ~0.3s |
| Boot do kernel + init do Alpine | ~1.3s |
| Import do scikit-learn | ~7.5s |
| Treinar o modelo | ~0.01s |
Olha o culpado aí. O import sklearn. Sozinho, ele come mais de 7 segundos. É um gordinho: carrega numpy, scipy, binários em C… É muita coisa pra arrastar do disco pra memória toda vez que a gente quer classificar uma frase simples.
A sacada é: e se a gente tirasse uma foto da VM depois que o scikit-learn já tá carregado? Economizaria esses 7+ segundos em toda execução subsequente.
A solução: snapshots
É exatamente o que acontece quando você fecha a tampa do notebook e ele hiberna. O sistema salva tudo no disco e desliga. Quando você abre, o Word e o Chrome estão lá, na mesma página, sem ter que carregar o Windows do zero. A VM nem sabe que foi “desligada”. Pra ela, foi um cochilo instantâneo.
Um snapshot do Firecracker captura dois arquivos:
- Memória da VM (
vm_mem): Todo o conteúdo da RAM, ou seja, código carregado, variáveis, estado dos processos - Estado da CPU (
vm_state): Registradores, program counter, estado da MMU
Com esses dois arquivos, você pode restaurar a VM exatamente no ponto onde ela estava. Não precisa fazer boot, não precisa carregar bibliotecas, não precisa inicializar nada. A VM “acorda” pronta pra trabalhar.
O fluxo
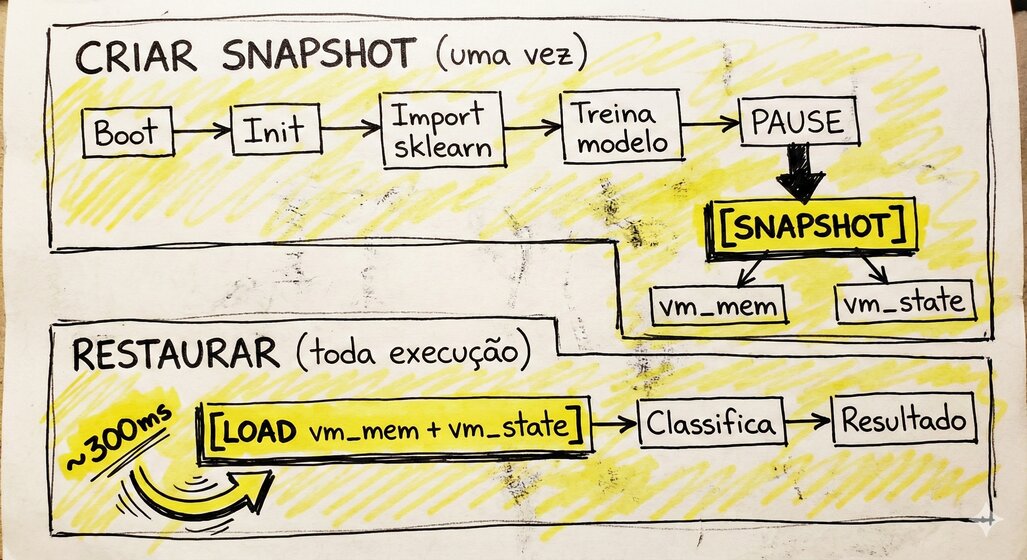
A primeira execução ainda é lenta (precisa criar o snapshot). Mas todas as seguintes pulam direto pro ponto onde a VM está pronta.
Nota: No nosso exemplo didático, a VM acorda num loop infinito de
sleep. Numa aplicação real, ela acordaria pronta pra ouvir um socket e processar requisições imediatamente.
Preparando o terreno
Se você acompanhou os artigos anteriores, já deve ter:
- Firecracker funcionando (artigo 1)
- nano-Lambda rodando (artigo 2)
- Python 3 (o
test-snapshot.pyusa só a biblioteca padrão, sempip install)
Agora a gente precisa de um rootfs com scikit-learn pra ter um cold start bem gordo e visível.
Um conselho de quem já travou a máquina fazendo isso: libera espaço. Sério. O rootfs tem 512MB, o snapshot mais 512MB… quando você vê, seu
/tmplotou e o Linux começa a reclamar. Garante pelo menos 1GB livre antes de rodar o script pra não passar raiva.
#!/bin/bash
# build-rootfs-sklearn.sh - Cria rootfs Alpine com scikit-learn para Firecracker
#
# Uso: ./build-rootfs-sklearn.sh
#
# Requer: Docker ou Podman, executar como root
set -e
ROOTFS="rootfs-sklearn.ext4"
SIZE_MB=512
MOUNT_POINT="/tmp/rootfs-sklearn-mount"
if command -v podman &> /dev/null; then
CONTAINER_CMD="podman"
elif command -v docker &> /dev/null; then
CONTAINER_CMD="docker"
else
echo "Erro: Docker ou Podman nao encontrado"
exit 1
fi
echo "Criando rootfs com scikit-learn"
echo "Container runtime: $CONTAINER_CMD"
echo "Tamanho: ${SIZE_MB}MB"
echo ""
if [ "$EUID" -ne 0 ]; then
echo "Erro: Execute como root (sudo ./build-rootfs-sklearn.sh)"
exit 1
fi
if [ -f "$ROOTFS" ]; then
echo "[*] Removendo rootfs anterior..."
rm -f "$ROOTFS"
fi
echo "[*] Criando imagem de ${SIZE_MB}MB..."
dd if=/dev/zero of=$ROOTFS bs=1M count=$SIZE_MB status=progress
mkfs.ext4 -F $ROOTFS
echo "[*] Montando imagem..."
mkdir -p $MOUNT_POINT
mount $ROOTFS $MOUNT_POINT
# Instala Alpine com sklearn
echo "[*] Instalando Alpine + Python + scikit-learn..."
$CONTAINER_CMD run --rm --privileged -v $MOUNT_POINT:/rootfs alpine:3.21 sh -c '
# Configura repositorios e chaves no rootfs target
mkdir -p /rootfs/etc/apk/keys
cp /etc/apk/repositories /rootfs/etc/apk/
cp -a /etc/apk/keys/* /rootfs/etc/apk/keys/
# Inicializa e instala pacotes
apk add --root /rootfs --initdb --no-scripts \
alpine-base \
python3 py3-numpy py3-scikit-learn py3-joblib
# Cria symlinks do busybox (--no-scripts nao executa os scripts de instalacao)
# Usa chroot para criar symlinks com paths corretos
chroot /rootfs /bin/busybox --install -s /bin
chroot /rootfs /bin/busybox --install -s /sbin
'
echo "[*] Criando estrutura de diretorios..."
mkdir -p $MOUNT_POINT/functions
mkdir -p $MOUNT_POINT/model
mkdir -p $MOUNT_POINT/snapshot
echo "[*] Criando init.sh..."
cat > $MOUNT_POINT/init.sh << 'INIT'
#!/bin/sh
# init.sh - Carrega sklearn, treina modelo e sinaliza pronto para snapshot
mount -t proc proc /proc
mount -t sysfs sysfs /sys
mount -t devtmpfs devtmpfs /dev 2>/dev/null || true
echo "=== Inicializando ambiente ML ==="
# PYTHONUNBUFFERED=1 garante que print() aparece imediatamente no console
PYTHONUNBUFFERED=1 python3 << 'PYEOF'
import time
start = time.time()
# Carrega bibliotecas (parte mais lenta)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
import_time = time.time() - start
print(f"[TIMING] sklearn importado em {import_time:.3f}s")
# Dados de treino para classificador de spam
texts = [
"ganhe dinheiro rapido agora",
"voce ganhou um premio clique aqui",
"oferta imperdivel so hoje gratis",
"parabens voce foi selecionado",
"clique aqui para ganhar",
"promocao especial limitada",
"reuniao amanha as 10h",
"relatorio do projeto em anexo",
"ola tudo bem com voce",
"podemos conversar depois",
"obrigado pela ajuda ontem",
"segue documento solicitado"
] * 10
labels = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0] * 10 # 1=spam, 0=ham
# Treina modelo
train_start = time.time()
model = Pipeline([
("tfidf", TfidfVectorizer()),
("clf", MultinomialNB())
])
model.fit(texts, labels)
train_time = time.time() - train_start
print(f"[TIMING] modelo treinado em {train_time:.3f}s")
print(f"[READY] VM pronta para snapshot")
PYEOF
# Sinaliza que esta pronto para snapshot
echo "SNAPSHOT_READY"
# Aguarda indefinidamente (sera pausado para snapshot)
while true; do
sleep 1
done
INIT
chmod +x $MOUNT_POINT/init.sh
# Cria handler de exemplo para uso apos restore
echo "[*] Criando handler de exemplo..."
cat > $MOUNT_POINT/functions/spam_handler.py << 'HANDLER'
#!/usr/bin/env python3
"""
Handler de classificacao de spam - executado apos restore do snapshot
"""
import sys
import json
# sklearn ja esta carregado na memoria (snapshot)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
def handler(text):
# Recria modelo (rapido, dados pequenos)
texts = [
"ganhe dinheiro rapido", "premio gratis clique",
"reuniao amanha", "relatorio anexo"
] * 5
labels = [1, 1, 0, 0] * 5
model = Pipeline([
("tfidf", TfidfVectorizer()),
("clf", MultinomialNB())
])
model.fit(texts, labels)
# Classifica
prediction = model.predict([text])[0]
proba = model.predict_proba([text])[0]
return {
"input": text,
"classification": "SPAM" if prediction == 1 else "HAM",
"confidence": float(max(proba)),
"probabilities": {
"spam": float(proba[1]),
"ham": float(proba[0])
}
}
if __name__ == "__main__":
# Le input
if len(sys.argv) > 1:
text = sys.argv[1]
else:
with open("/functions/input.txt", "r") as f:
text = f.read().strip()
result = handler(text)
print("JSON_RESULT_START")
print(json.dumps(result, indent=2))
print("JSON_RESULT_END")
HANDLER
chmod +x $MOUNT_POINT/functions/spam_handler.py
echo "[*] Desmontando..."
umount $MOUNT_POINT
rmdir $MOUNT_POINT
SIZE=$(du -h $ROOTFS | cut -f1)
echo ""
echo "=== Rootfs criado com sucesso ==="
echo "Arquivo: $ROOTFS"
echo "Tamanho: $SIZE"
echo ""
echo "Proximo passo: execute test-snapshot.py para testar"Execute o script (precisa de root por causa do mount):
chmod +x build-rootfs-sklearn.sh
sudo ./build-rootfs-sklearn.shO momento certo do snapshot
Aqui tem um “pulo do gato” que se você errar, nada funciona. O timing.
Se pausar cedo demais, o scikit-learn não carregou. O snapshot vai capturar a VM no meio do import, e você não ganha nada. Se pausar tarde, perdeu tempo. A gente precisa que a VM grite “Tô pronta!” antes de congelar.
A solução é um “aperto de mão” entre a VM e o host:
- A VM carrega tudo que precisa
- A VM imprime um marcador:
SNAPSHOT_READY - O host monitora o output da VM
- Quando vê o marcador, pausa e tira o snapshot
Esse padrão é tão comum que vale destacar:
# Dentro da VM (init.sh)
print("SNAPSHOT_READY") # Sinaliza pro host
# No host (orquestrador)
while True:
output = read_vm_console()
if "SNAPSHOT_READY" in output:
pause_vm()
create_snapshot()
breakSem esse handshake, você fica no escuro, pode acabar capturando uma VM ainda em inicialização.
Implementando o teste
Vamos criar um script que:
- Mede o cold start completo
- Cria um snapshot
- Mede o tempo de restore
#!/usr/bin/env python3
"""
test-snapshot.py - Compara cold start vs restore no Firecracker
Mede tempos de:
1. Cold start (boot completo + carga sklearn)
2. Criar snapshot
3. Restore do snapshot
Uso:
sudo python3 test-snapshot.py
Requer:
- Firecracker binario (./firecracker)
- Kernel Linux (./vmlinux.bin)
- Rootfs com sklearn (./rootfs-sklearn.ext4)
Sem dependencias externas: usa so a biblioteca padrao do Python
(socket + http.client falam com o socket Unix da API do Firecracker).
"""
import subprocess
import time
import shutil
import tempfile
import os
import sys
import json
import socket
import http.client
# Configuracoes
FIRECRACKER_BIN = "./firecracker"
KERNEL_PATH = "./vmlinux.bin"
ROOTFS_TEMPLATE = "./rootfs-sklearn.ext4"
SOCKET_PATH = "/tmp/fc-snapshot-test.socket"
SNAPSHOT_PATH = "/tmp/fc-snapshot"
MEM_FILE = "/tmp/fc-snapshot/vm_mem"
SNAPSHOT_FILE = "/tmp/fc-snapshot/vm_state"
VCPU_COUNT = 1
MEM_SIZE_MIB = 512
# Marcador de handshake - VM imprime isso quando esta pronta
READY_MARKER = "SNAPSHOT_READY"
class UnixHTTPConnection(http.client.HTTPConnection):
"""HTTPConnection que fala por um socket Unix em vez de TCP."""
def __init__(self, socket_path):
super().__init__("localhost")
self.socket_path = socket_path
def connect(self):
sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)
sock.connect(self.socket_path)
self.sock = sock
def call_api(method, path, data=None):
conn = UnixHTTPConnection(SOCKET_PATH)
body = json.dumps(data) if data is not None else None
headers = {"Accept": "application/json", "Content-Type": "application/json"}
conn.request(method, path, body=body, headers=headers)
resp = conn.getresponse()
status = resp.status
text = resp.read().decode("utf-8", "replace")
conn.close()
if status >= 400:
raise Exception(f"API error {status}: {text}")
return status, text
def check_dependencies():
"""Verifica se todos os arquivos necessarios existem."""
missing = []
for path, desc in [
(FIRECRACKER_BIN, "Firecracker"),
(KERNEL_PATH, "Kernel"),
(ROOTFS_TEMPLATE, "Rootfs sklearn")
]:
if not os.path.exists(path):
missing.append(f" - {desc}: {path}")
if missing:
print("Erro: Arquivos necessarios nao encontrados:")
print("\n".join(missing))
print("\nExecute primeiro:")
print(" 1. Baixe o Firecracker e kernel (ver artigo 01)")
print(" 2. Execute: ./build-rootfs-sklearn.sh")
sys.exit(1)
def cleanup():
"""Limpa processos e arquivos de execucoes anteriores."""
subprocess.run(["pkill", "-9", "-x", "firecracker"], capture_output=True)
time.sleep(1)
if os.path.exists(SOCKET_PATH):
os.remove(SOCKET_PATH)
if os.path.exists(SNAPSHOT_PATH):
shutil.rmtree(SNAPSHOT_PATH)
def wait_for_ready(log_file, timeout=60):
"""
Aguarda a VM sinalizar que esta pronta para snapshot.
O handshake e importante: sem ele, voce pode tirar snapshot
com a VM ainda carregando bibliotecas.
"""
start = time.time()
while time.time() - start < timeout:
if os.path.exists(log_file):
with open(log_file, "r") as f:
if READY_MARKER in f.read():
return True
time.sleep(0.1)
return False
def prepare_rootfs_for_snapshot():
"""Copia rootfs para uso temporario (init.sh ja incluso no rootfs)."""
temp_rootfs = tempfile.NamedTemporaryFile(suffix=".ext4", delete=False).name
shutil.copy(ROOTFS_TEMPLATE, temp_rootfs)
return temp_rootfs
def start_firecracker(log_file=None):
if os.path.exists(SOCKET_PATH):
os.remove(SOCKET_PATH)
stdout = open(log_file, "w") if log_file else subprocess.DEVNULL
proc = subprocess.Popen(
[FIRECRACKER_BIN, "--api-sock", SOCKET_PATH],
stdout=stdout,
stderr=subprocess.STDOUT
)
for _ in range(50):
if os.path.exists(SOCKET_PATH):
break
time.sleep(0.1)
else:
raise Exception("Timeout esperando socket")
time.sleep(0.2)
return proc
def configure_vm(rootfs_path):
call_api("PUT", "/boot-source", {
"kernel_image_path": KERNEL_PATH,
"boot_args": "console=ttyS0 reboot=k panic=1 pci=off init=/init.sh"
})
call_api("PUT", "/drives/rootfs", {
"drive_id": "rootfs",
"path_on_host": rootfs_path,
"is_root_device": True,
"is_read_only": False
})
call_api("PUT", "/machine-config", {
"vcpu_count": VCPU_COUNT,
"mem_size_mib": MEM_SIZE_MIB
})
def main():
print("=" * 60)
print("Teste de Snapshot/Restore do Firecracker")
print("=" * 60)
print()
print("NOTA: Esta VM esta isolada (sem rede).")
print(" Para acesso a internet, veja o artigo sobre networking.")
print()
check_dependencies()
cleanup()
# Variaveis para cleanup em caso de erro
rootfs = None
fc_proc = None
fc_proc2 = None
try:
# PARTE 1: Cold Start
print("\n[1] COLD START (boot + sklearn)")
print("-" * 40)
cold_start = time.time()
rootfs = prepare_rootfs_for_snapshot()
print(f" Rootfs preparado ({time.time() - cold_start:.3f}s)")
log_file = "/tmp/fc-boot.log"
fc_proc = start_firecracker(log_file)
print(f" Firecracker iniciado ({time.time() - cold_start:.3f}s)")
configure_vm(rootfs)
print(f" VM configurada ({time.time() - cold_start:.3f}s)")
call_api("PUT", "/actions", {"action_type": "InstanceStart"})
print(" VM iniciada - aguardando SNAPSHOT_READY...")
# Aguarda a VM sinalizar que esta pronta (handshake)
if not wait_for_ready(log_file, timeout=60):
print(" ERRO: Timeout esperando a VM ficar pronta")
return
cold_time = time.time() - cold_start
print(f"\n >>> COLD START TOTAL: {cold_time:.3f}s")
# Mostra timing do sklearn
with open(log_file, "r") as f:
for line in f:
if "[TIMING]" in line or "[READY]" in line:
print(f" {line.strip()}")
# PARTE 2: Criar Snapshot
print("\n[2] CRIANDO SNAPSHOT")
print("-" * 40)
snapshot_start = time.time()
call_api("PATCH", "/vm", {"state": "Paused"})
print(f" VM pausada ({time.time() - snapshot_start:.3f}s)")
os.makedirs(SNAPSHOT_PATH, exist_ok=True)
call_api("PUT", "/snapshot/create", {
"snapshot_type": "Full",
"snapshot_path": SNAPSHOT_FILE,
"mem_file_path": MEM_FILE
})
snapshot_time = time.time() - snapshot_start
print(f" Snapshot criado ({snapshot_time:.3f}s)")
# Tamanhos
mem_size = os.path.getsize(MEM_FILE) / (1024 * 1024)
state_size = os.path.getsize(SNAPSHOT_FILE) / 1024
print(f" Memoria: {mem_size:.1f} MB | Estado: {state_size:.1f} KB")
# Para a VM original
fc_proc.terminate()
fc_proc.wait()
fc_proc = None # Marca como ja limpo
if os.path.exists(SOCKET_PATH):
os.remove(SOCKET_PATH)
print(" VM original terminada")
# PARTE 3: Restore
print("\n[3] RESTORE DO SNAPSHOT")
print("-" * 40)
restore_start = time.time()
fc_proc2 = start_firecracker()
print(f" Firecracker iniciado ({time.time() - restore_start:.3f}s)")
call_api("PUT", "/snapshot/load", {
"snapshot_path": SNAPSHOT_FILE,
"mem_backend": {
"backend_type": "File",
"backend_path": MEM_FILE
},
"enable_diff_snapshots": False,
"resume_vm": True
})
restore_time = time.time() - restore_start
print(f"\n >>> RESTORE TOTAL: {restore_time:.3f}s")
# RESUMO
print("\n" + "=" * 60)
print("RESULTADOS")
print("=" * 60)
print(f" Cold Start: {cold_time:.3f}s")
print(f" Criar Snapshot: {snapshot_time:.3f}s")
print(f" Restore: {restore_time:.3f}s")
print()
print(f" Speedup: {cold_time / restore_time:.1f}x mais rapido")
print(f" Economia: {cold_time - restore_time:.3f}s por execucao")
print("=" * 60)
return {
"cold_start": cold_time,
"snapshot": snapshot_time,
"restore": restore_time,
"speedup": cold_time / restore_time
}
finally:
# Cleanup robusto: libera recursos mesmo em caso de erro
if fc_proc2:
try:
fc_proc2.terminate()
fc_proc2.wait(timeout=5)
except Exception:
pass
if fc_proc:
try:
fc_proc.terminate()
fc_proc.wait(timeout=5)
except Exception:
pass
if rootfs and os.path.exists(rootfs):
try:
os.remove(rootfs)
except Exception:
pass
if os.path.exists(SOCKET_PATH):
try:
os.remove(SOCKET_PATH)
except Exception:
pass
if __name__ == "__main__":
if os.geteuid() != 0:
print("Erro: Execute como root (sudo)")
sys.exit(1)
main()Executando o teste
sudo python3 test-snapshot.pyResultado no meu ambiente:
============================================================
Teste de Snapshot/Restore do Firecracker
============================================================
NOTA: Esta VM esta isolada (sem rede).
Para acesso a internet, veja o artigo sobre networking.
[1] COLD START (boot + sklearn)
----------------------------------------
Rootfs preparado (0.141s)
Firecracker iniciado (0.442s)
VM configurada (0.443s)
VM iniciada - aguardando SNAPSHOT_READY...
>>> COLD START TOTAL: 9.280s
[TIMING] sklearn importado em 7.485s
[TIMING] modelo treinado em 0.009s
[READY] VM pronta para snapshot
[2] CRIANDO SNAPSHOT
----------------------------------------
VM pausada (0.001s)
Snapshot criado (0.179s)
Memoria: 512.0 MB | Estado: 13.5 KB
VM original terminada
[3] RESTORE DO SNAPSHOT
----------------------------------------
Firecracker iniciado (0.301s)
>>> RESTORE TOTAL: 0.305s
============================================================
RESULTADOS
============================================================
Cold Start: 9.280s
Criar Snapshot: 0.179s
Restore: 0.305s
Speedup: 30.5x mais rapido
Economia: 8.976s por execucao
============================================================Seus números vão variar um pouco. O cold start fica entre 8 e 10 segundos (o
importdo scikit-learn sozinho come uns 7), e a criação do snapshot oscila com o cache de disco (a primeira rodada costuma ser mais lenta). O restore é o número que não muda: sempre na casa dos 300ms. Roda duas ou três vezes pra ver.
~300 milissegundos. Piscou, perdeu. Saímos de uma espera de cafézinho (~9s) para algo instantâneo. É mais de 30x mais rápido. A sensação de usar muda da água pro vinho.
Por que isso importa
Não parece muito no papel. Mas na prática, a diferença é brutal:
- ~9 segundos: O usuário clica, vê uma tela carregando, tem tempo de pensar “travou?”, considera fechar a aba. É uma eternidade em interações web.
- ~300 milissegundos: Imperceptível. Qualquer coisa abaixo de 300-400ms é sentida como “instantânea”. O usuário nem percebe que esperou.
O trade-off: CPU por Storage
Olha os tamanhos dos arquivos de snapshot:
- Memória: 512MB (toda a RAM da VM)
- Estado: ~14KB (registradores, program counter)
Você está trocando ~9 segundos de CPU por 512MB de disco. Em nuvem, esse trade-off quase sempre compensa: armazenamento é barato, tempo de computação e paciência do usuário são caros.
Nota técnica: Os ~300ms incluem o tempo de iniciar o processo Firecracker do zero (~300ms). O restore da memória em si leva poucos milissegundos. Orquestradores de alta performance (como o Lambda por baixo dos panos) mantêm processos “pré-aquecidos”, reduzindo o tempo total para 20-50ms.
O que está acontecendo por baixo
Quando você chama /snapshot/create, o Firecracker:
- Pausa a vCPU: para a execução do guest no ponto exato
- Serializa registradores: salva PC, SP, flags, todos os registradores
- Dumpa a memória: escreve toda a RAM guest num arquivo
- Salva estado de dispositivos: serial, block devices, etc
No restore:
- Aloca memória: reserva RAM pro guest
- Carrega dump: mapeia o arquivo de memória
- Restaura registradores: coloca CPU virtual no estado salvo
- Resume: execução continua exatamente onde parou
A VM literalmente “acorda” no meio de um sleep(1). Ela não sabe que foi pausada, serializada pra disco, e restaurada numa instância nova do Firecracker. Pra ela, foi um cochilo instantâneo.
Escala horizontal: múltiplas VMs do mesmo snapshot
E aqui que a coisa fica interessante de verdade. Um snapshot pode ser usado pra criar múltiplas VMs ao mesmo tempo. Cada uma começa no mesmo estado, mas evolui independentemente.
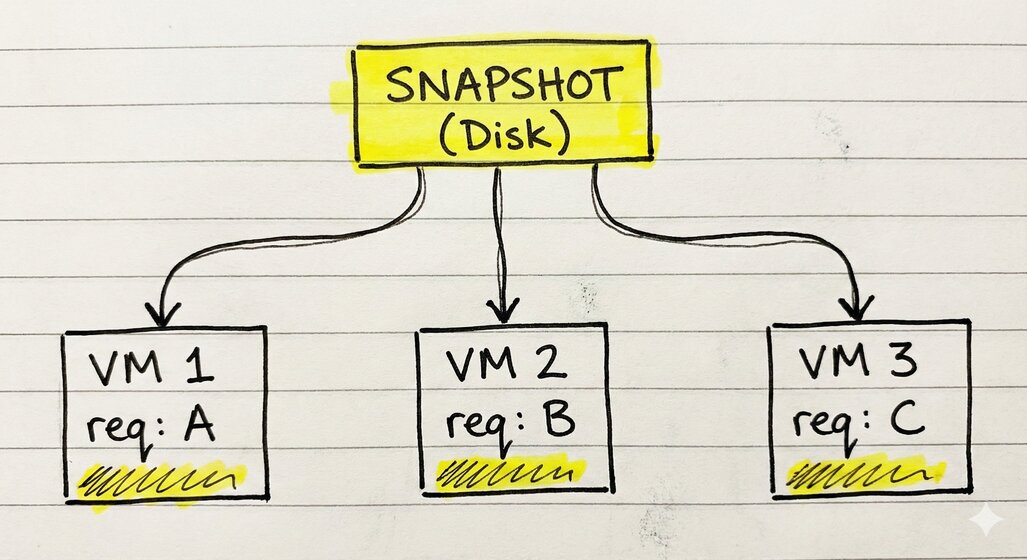
Isso é exatamente o que serviços como Lambda fazem pra escalar. Um snapshot “dourado” com o runtime pronto, e dezenas de VMs sendo restauradas dele conforme as requisições chegam.
O custo de inicialização pesado (carregar bibliotecas, treinar modelo) é pago uma vez. Todas as execuções subsequentes pagam só o custo do restore.
Dica de ouro pra produção: Copy-on-Write. Sabe aquele arquivo de 512MB da memória? Você não precisa copiar ele pra cada nova VM. Você pode fazer 100 VMs lerem o mesmo arquivo ao mesmo tempo. O Linux cuida da mágica, só copia as páginas que cada VM modifica. Resultado? Você sobe um exército de Lambdas gastando quase a mesma RAM de um só.
Quando usar snapshots
Snapshots fazem mais sentido quando:
- Inicialização é cara: Carregar ML models, conectar em bancos, aquecer caches
- Execuções são frequentes: O custo do snapshot se dilui em muitas restaurações
- Estado inicial é previsível: Você pode criar um snapshot “genérico” que serve pra várias requisições
Não faz sentido quando:
- Inicialização é rápida: Se sua função carrega em 50ms, o overhead do snapshot não compensa
- Estado varia muito: Se cada execução precisa de configuração diferente, um snapshot genérico não ajuda
- Execuções são raras: O snapshot fica obsoleto, você gasta tempo criando algo que mal usa
Conclusão
Pronto. Agora você sabe como o Lambda consegue responder em milissegundos mesmo rodando VMs completas por baixo. Não é mágica, é engenharia cuidadosa com snapshots.
Se você notou que essa VM está isolada (sem rede), a Parte 03 já cobre isso: TAP devices, NAT e como dar acesso à internet pra sua microVM.
Com snapshots + networking, você tem quase todas as peças. Falta uma: em produção, ninguém fica rodando scripts Python na mão. No próximo artigo, a gente daemoniza as microVMs com systemd, pra elas iniciarem no boot, reiniciarem se morrerem, e se comportarem como serviços de verdade.
Arquivos deste artigo:
build-rootfs-sklearn.sh: script pra criar rootfs com scikit-learntest-snapshot.py: teste comparando cold start vs restore
| Números reais medidos: | Métrica | Valor |
|---|---|---|
| Cold Start | ~9s | |
| Restore | ~300ms | |
| Speedup | ~30x | |
| Tamanho memória | 512MB | |
| Tamanho estado | ~14KB |



Comentários
Comentários fechados para visitantes. Entre ou registre-se para comentar.