
Atualizado em 24/05/2026; Graylog 7.0.7
Série CSI do Linux
- Parte 01: Montando seu servidor de logs com Graylog (você está aqui)
- Parte 02: Gravando sessões de terminal com tlog
- Parte 03: Transformando logs em alertas
Sabe aquela sensação de quando o servidor cai às 2 da manhã e você precisa descobrir o que aconteceu? Você entra via SSH, vai direto no /var/log/… e o disco encheu. Ou pior: a máquina reiniciou e levou junto aquele log que explicava tudo.
Agora multiplica isso por 50 servidores. Boa sorte brincando de detetive.
O problema real
Logs espalhados são logs perdidos. Simples assim.
Estou atualizando um post antigo sobre o rootsh (um keylogger de terminal), mas percebi uma coisa óbvia que tinha ignorado: não adianta nada gravar o que o usuário digita se esse log fica preso na máquina local. Se um invasor ganha root, a primeira coisa que ele faz é apagar os rastros.
Então antes de falar sobre auditoria de terminal, gravação de sessões, ou qualquer coisa mais avançada… a gente precisa de uma fundação sólida. Uma “caixa forte” centralizada onde todos os logs da sua rede vão morar. Longe das mãos de quem quer apagar evidências.
Este é o primeiro artigo de uma série sobre auditoria. Aqui a gente monta o servidor de logs. Nos próximos, vamos plugar as coisas interessantes nele.
A escolha das ferramentas (Stack 2026)
Antes de sair instalando coisa, deixa eu explicar por que escolhi essas ferramentas. Não quero que você siga receita de bolo sem entender o cardápio.
Por que não ELK?
Se você pesquisou sobre logs centralizados, com certeza esbarrou no tal do ELK Stack (Elasticsearch, Logstash, Kibana). Era o padrão da indústria… até a Elastic mudar a licença e complicar a vida de todo mundo.
Além disso, ELK é pesado. Precisa de bastante RAM, bastante disco, e uma paciência considerável pra configurar. Funciona muito bem em empresas grandes com equipe dedicada. Pra quem está montando um lab ou quer algo mais direto ao ponto, é bazuca pra matar mosca.
A solução: Graylog + OpenSearch
O mundo open source não ficou parado quando a Elastic mudou as regras do jogo. A Amazon fez um fork chamado OpenSearch, que é 100% open source e compatível com o que o Elasticsearch fazia.
O Graylog abraçou essa mudança. Ele usa o OpenSearch como motor de busca e armazenamento, mas te entrega uma interface muito mais amigável e focada em logs. Menos firula, mais resultado.
Por que Podman?
Podman já vem instalado por padrão no Fedora e é praticamente idêntico ao Docker em termos de comandos. Se você prefere Docker, pode usar sem problemas, só troque podman-compose por docker compose nos comandos.
Pré-requisitos
Antes de começar, você vai precisar de:
- Um servidor Linux – Uma VM simples resolve. Fedora 44+, RHEL 9 ou Ubuntu 24.04 LTS funcionam bem. Recomendo pelo menos 4GB de RAM e uns 64GB de disco pra começar.
- Podman e podman-compose instalados – Na maioria das distros, a instalação é direta via gerenciador de pacotes (
dnf install podman podman-composeno Fedora/RHEL ouapt install podman podman-composeno Debian/Ubuntu). - Git – Pra clonar o repositório com os arquivos de configuração (
dnf install gitno Fedora/RHEL ouapt install gitno Debian/Ubuntu).
O ajuste que ninguém avisa
O OpenSearch é exigente com um parâmetro do kernel chamado vm.max_map_count. Ele controla quantas áreas de memória mapeada um processo pode ter. O OpenSearch precisa de muitas. Sem isso, ele reclama e morre.
Primeiro, confira o valor atual:
sysctl vm.max_map_countSe o resultado for 262144 ou maior, está tudo certo. Fedora 44+ e algumas distros recentes já vêm com um valor alto o suficiente. Nesse caso, pule este passo.
Se o valor for menor que 262144, ajuste:
# Ajuste temporário (some no reboot)
sudo sysctl -w vm.max_map_count=262144
# Ajuste permanente (sobrevive ao reboot)
echo "vm.max_map_count=262144" | sudo tee /etc/sysctl.d/01-max-map-count.conf
sudo sysctl --systemUsar /etc/sysctl.d/ ao invés de editar o /etc/sysctl.conf diretamente é a forma moderna de fazer isso. Mais organizado, mais fácil de remover depois se precisar.
Mão na massa: O arquivo compose.yaml
Todos os arquivos deste artigo estão disponíveis no repositório. Clone e entre no diretório:
git clone https://github.com/dklima/csi-do-linux.git
cd csi-do-linux/01-graylogAntes de mais nada, copie o arquivo de exemplo de variáveis de ambiente:
cp .env.example .envO compose.yaml é o coração da operação. Vamos dar uma olhada no que tem dentro:
services:
mongodb:
image: docker.io/mongo:7.0
container_name: mongodb
volumes:
- mongodb_data:/data/db
restart: unless-stopped
opensearch:
image: docker.io/opensearchproject/opensearch:2.19.0
container_name: opensearch
environment:
- discovery.type=single-node
- plugins.security.disabled=true
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms1g -Xmx1g"
- OPENSEARCH_INITIAL_ADMIN_PASSWORD=${OPENSEARCH_INITIAL_ADMIN_PASSWORD}
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- opensearch_data:/usr/share/opensearch/data
restart: unless-stopped
graylog:
image: docker.io/graylog/graylog:7.0
container_name: graylog
environment:
- GRAYLOG_PASSWORD_SECRET=${GRAYLOG_PASSWORD_SECRET}
- GRAYLOG_ROOT_PASSWORD_SHA2=${GRAYLOG_ROOT_PASSWORD_SHA2}
- GRAYLOG_HTTP_EXTERNAL_URI=${GRAYLOG_HTTP_EXTERNAL_URI}
- GRAYLOG_ELASTICSEARCH_HOSTS=http://opensearch:9200
- GRAYLOG_MONGODB_URI=mongodb://mongodb:27017/graylog
ports:
- "9000:9000" # Interface web
- "1514:1514/udp" # Syslog UDP
- "1514:1514/tcp" # Syslog TCP
depends_on:
- mongodb
- opensearch
restart: unless-stopped
volumes:
mongodb_data:
opensearch_data:Os volumes mongodb_data e opensearch_data guardam todos os dados fora dos containers. Na prática, isso significa que você pode parar e subir os containers quantas vezes quiser (podman-compose down / up -d) sem perder configurações ou logs. Os dados só somem se você remover os volumes de propósito (podman volume rm).
O que cada peça faz
- MongoDB: Guarda as configurações do Graylog. Usuários, dashboards, regras de alertas… tudo fica aqui.
- OpenSearch: É onde os logs brutos moram. Quando você pesquisa algo na interface, é ele que processa a busca.
- Graylog: O cérebro da operação. Recebe os logs, processa, indexa no OpenSearch, e te mostra tudo numa interface web.
As portas expostas são:
- 9000: Interface web. É onde você vai acessar o Graylog.
- 1514: Onde os logs chegam. Usamos uma porta alta porque portas abaixo de 1024 precisam de root.
Atenção com versões do OpenSearch
Se você está lendo isso no futuro e pensou em usar uma versão mais recente do OpenSearch, cuidado: o Graylog não suporta OpenSearch 3.x. A API mudou e vai quebrar a integração. Fique na série 2.x até que a compatibilidade seja oficialmente anunciada.
A pegadinha da primeira configuração
Antes de subir os containers, precisamos configurar o arquivo .env que copiamos antes. O arquivo tem quatro variáveis que definem as credenciais do sistema:
GRAYLOG_PASSWORD_SECRET: Uma frase secreta pra criptografia. Precisa ter pelo menos 16 caracteres. O comando abaixo gera uma string segura:
openssl rand -base64 32GRAYLOG_ROOT_PASSWORD_SHA2: A senha do usuário admin, em SHA256. O Graylog não aceita senha em texto puro por motivos óbvios. Pra gerar o hash da sua senha:
printf '%s' "SuaSenhaForte123" | sha256sum | cut -d' ' -f1Use
printf '%s' ao invés de echo -n. O bash pode escapar caracteres especiais como ! de forma inesperada, gerando um hash diferente do esperado. Evite usar ! na senha pra não ter dor de cabeça.
O resultado vai ser algo tipo:
8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918Esse hash vai pro .env.
GRAYLOG_HTTP_EXTERNAL_URI: O IP ou hostname do servidor. Aqui entra o IP real da máquina no lugar de SEU_IP. Pra acesso local, 127.0.0.1 funciona.
OPENSEARCH_INITIAL_ADMIN_PASSWORD: O OpenSearch 2.12+ exige uma senha inicial, mesmo que a gente desabilite a segurança depois. Precisa ser uma senha forte: mínimo 8 caracteres, com maiúscula, minúscula, número e caractere especial. Algo tipo S3cur3P@ssw0rd1Lab.
Com o .env configurado, agora podemos subir os containers:
sudo podman-compose up -dO Podman em modo rootless usa o
aardvark-dns para resolução de nomes entre containers, e esse serviço precisa bindar na porta 53, que é uma porta privilegiada (abaixo de 1024). Além disso, o mapeamento de portas no modo rootless tem limitações que podem impedir o acesso externo ao servidor.
Troubleshooting: Conflito com DNS local
Se o servidor usa Cockpit, libvirt, Pi-hole, ou qualquer outro serviço que ocupe a porta 53 (dnsmasq, bind, systemd-resolved), os containers não sobem. O erro se parece com isso:
[opensearch] | Error: unable to start container ...
[opensearch] | Error starting server failed to bind udp listener on 10.89.0.1:53: IO error: Address already in use (os error 98)O problema é que o aardvark-dns do Podman tenta usar a porta 53 na interface de rede dos containers, mas ela já está ocupada.
Solução: Desabilitar o DNS interno do Podman e usar IPs fixos para os containers. O repositório inclui um arquivo compose-no-dns.yaml já configurado pra isso.
Primeiro, paramos tudo e recriamos a rede com subnet definida:
# Para os containers se estiverem rodando
sudo podman-compose down
# Remove a rede padrão do podman-compose (geralmente chamada de 01-graylog_default ou similar)
sudo podman network ls
sudo podman network rm 01-graylog_default
# Cria uma nova rede sem DNS interno, com subnet definida
sudo podman network create --disable-dns --subnet 172.20.0.0/24 graylog-netDepois, usamos o compose alternativo que já tem os IPs configurados:
sudo podman-compose -f compose-no-dns.yaml up -dO compose-no-dns.yaml atribui IPs fixos pra cada container e referencia eles diretamente nas variáveis de ambiente do Graylog:
- MongoDB: 172.20.0.10
- OpenSearch: 172.20.0.11
- Graylog: 172.20.0.12
Sem o DNS interno, a resolução por nome (mongodb, opensearch) não funciona, por isso usamos IPs diretamente.
A primeira inicialização leva uns 2-3 minutos porque o OpenSearch precisa preparar seus índices. Dá pra acompanhar o progresso com:
sudo podman-compose logs -f graylogQuando aparecer algo como Graylog server up and running, você está pronto.
Acesse http://SEU_IP:9000 no navegador. O login é:
- Usuário: admin
- Senha: aquela que você usou pra gerar o SHA256

No primeiro login, o Graylog mostra um popup pedindo autorização pra coletar dados anônimos de uso. Pode cancelar ou aceitar, isso não afeta o funcionamento.
Criando o input (Ensinando o Graylog a ouvir)
O Graylog vem “surdo” por padrão. Ele não escuta nenhuma porta até a gente configurar. Isso é proposital: te obriga a pensar no que quer receber.
Pra criar nosso primeiro input, o caminho na interface web é:
System > Inputs > selecionar Syslog UDP no dropdown > Launch new input
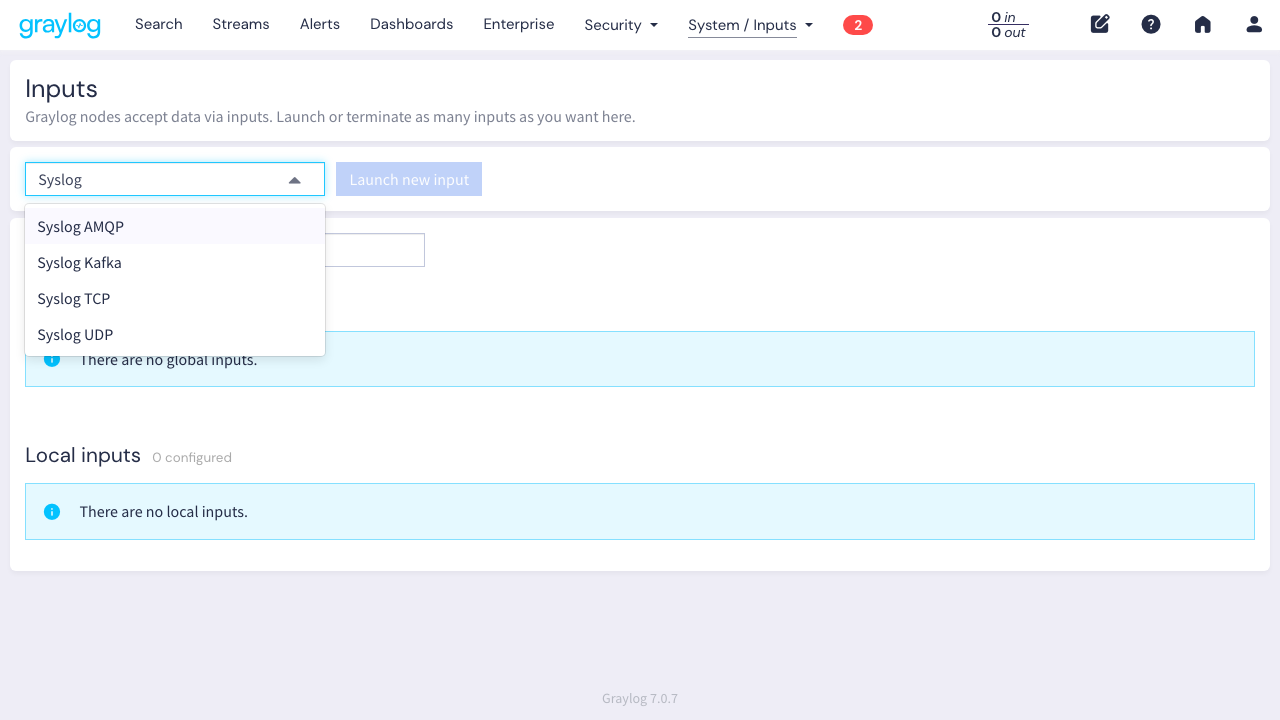
Na janela que abre, as configurações importantes são:
- Global: Deixe o checkbox marcado (vem marcado por padrão). Isso faz o input funcionar em qualquer node do cluster.
- Title: Algo descritivo tipo “Syslog UDP – Geral”
- Port: Mude de 514 para 1514. A porta padrão 514 precisa de root, e nosso Graylog roda dentro de um container. A porta 1514 funciona sem essa restrição.
- O resto pode ficar no padrão
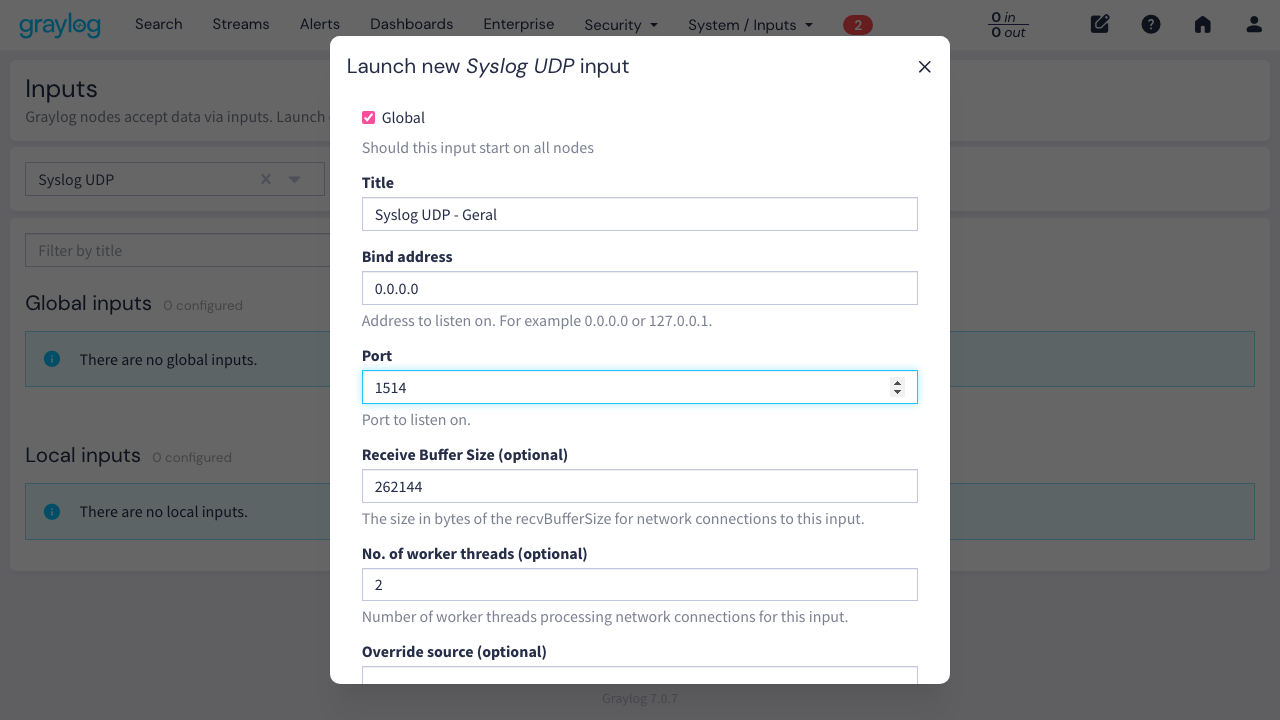
Depois de confirmar com Launch input, o input é criado em modo de configuração (aparece um badge amarelo “1 SETUP”). Isso é normal no Graylog 7.x.
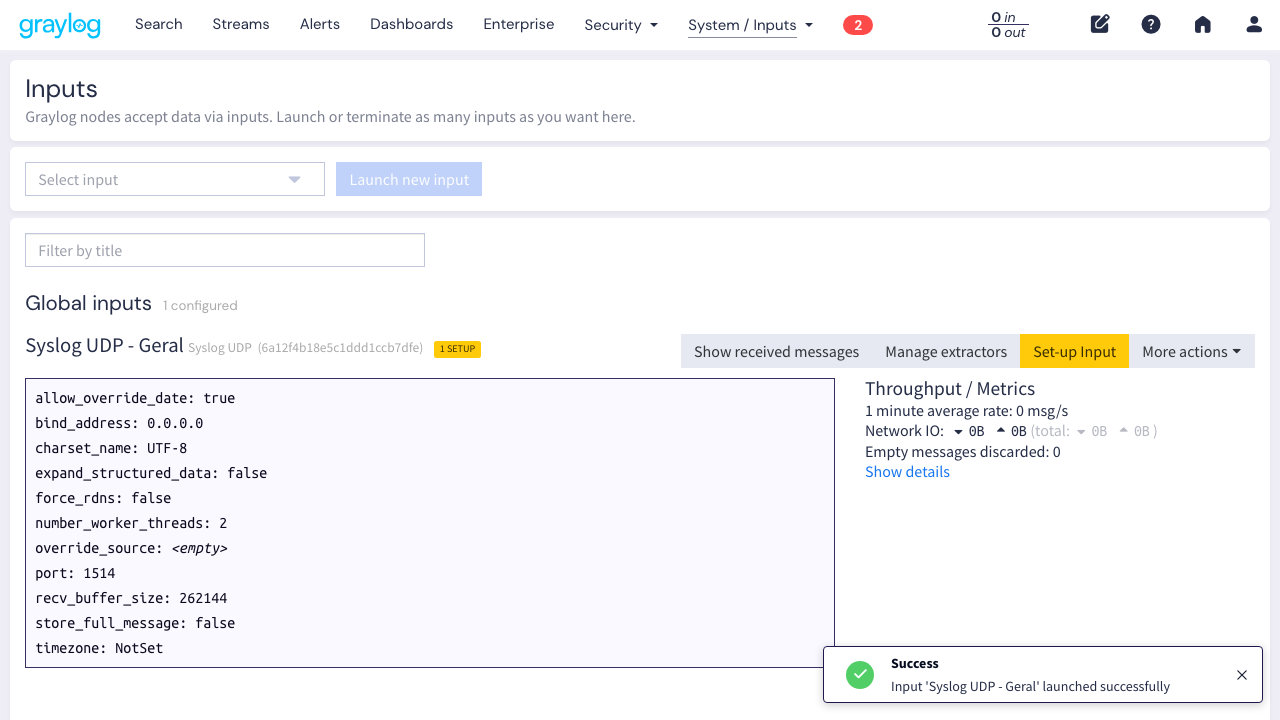
Para ativá-lo:
- Clique em More actions > Exit Setup mode
- O botão Start input vai aparecer. Clique nele.
- Quando o botão mudar para Stop input (vermelho), o input está rodando e pronto pra receber logs.
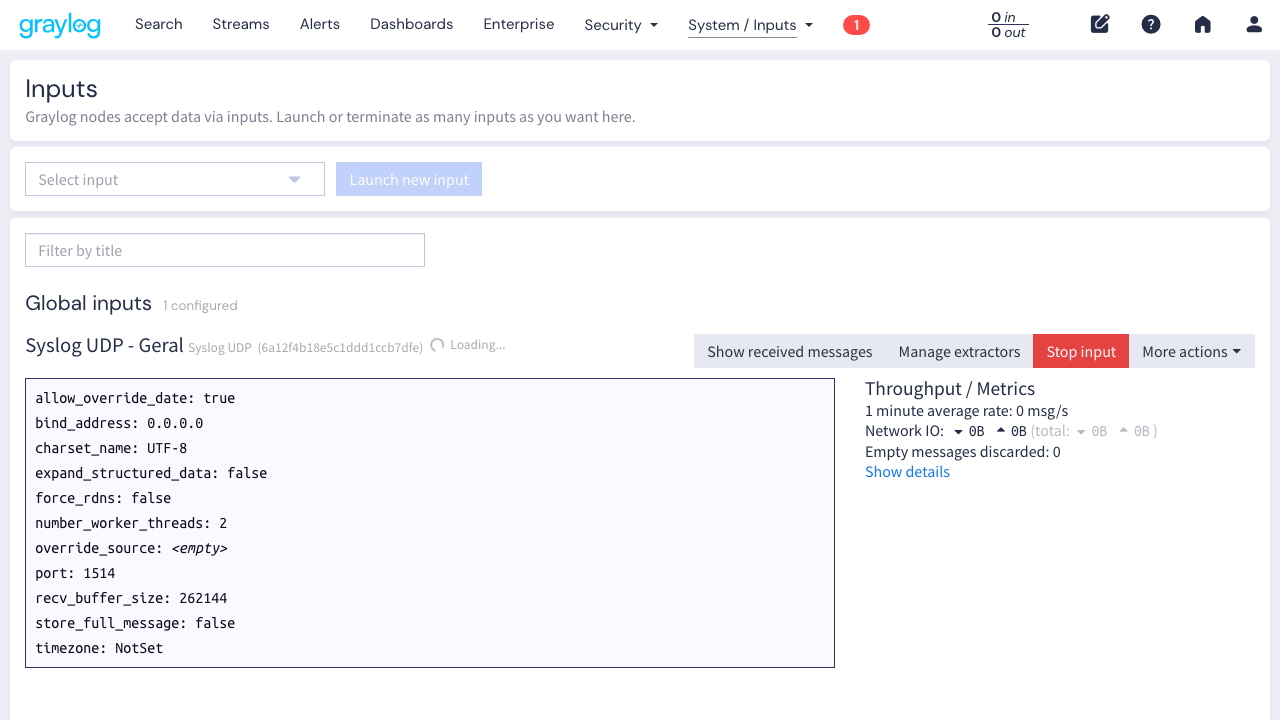
Verifique se o input saiu do modo SETUP: clique em “More actions” e veja se aparece “Exit Setup mode”. Depois de sair do SETUP, clique em “Start input”. Se mesmo assim não funcionar, reinicie o container do Graylog:
sudo podman restart graylog
Por que UDP?
Pra logs em massa, UDP é a escolha certa. Ele funciona no esquema “dispara e esquece”, o cliente manda o log e segue a vida, sem esperar confirmação.
Com TCP, se a rede engasgar ou o servidor de logs ficar lento, o cliente trava esperando resposta. Em cenários de alta carga, isso pode virar uma bola de neve e derrubar sistemas.
UDP pode perder um pacote aqui e ali? Pode. Mas pra logs, geralmente é um trade-off aceitável. Você prefere perder uma mensagem ocasional ou travar seu servidor de produção?
O teste de fogo
Não vamos configurar clientes reais ainda, isso fica pro próximo artigo. Mas a gente precisa saber se essa bagaça está funcionando.
De qualquer máquina Linux na mesma rede (ou do próprio servidor), dá pra enviar um log de teste:
# Usando logger (a forma mais confiável)
logger -n SEU_IP -P 1514 --udp "Primeiro log remoto - foi, sera?"
# Ou usando netcat (precisa do prefixo syslog pra funcionar direito)
echo "<14>Teste do Graylog - Agora vai!" | nc -u -w 1 SEU_IP 1514O logger já formata a mensagem no padrão syslog automaticamente. O netcat manda texto cru, então a gente precisa colocar o <14> na frente. Esse número é o priority do syslog (facility + severity). Sem ele, o Graylog não sabe interpretar a mensagem direito.
Na interface do Graylog, clique em Search no menu. As mensagens recebidas aparecem listadas, indexadas e prontas pra pesquisa.
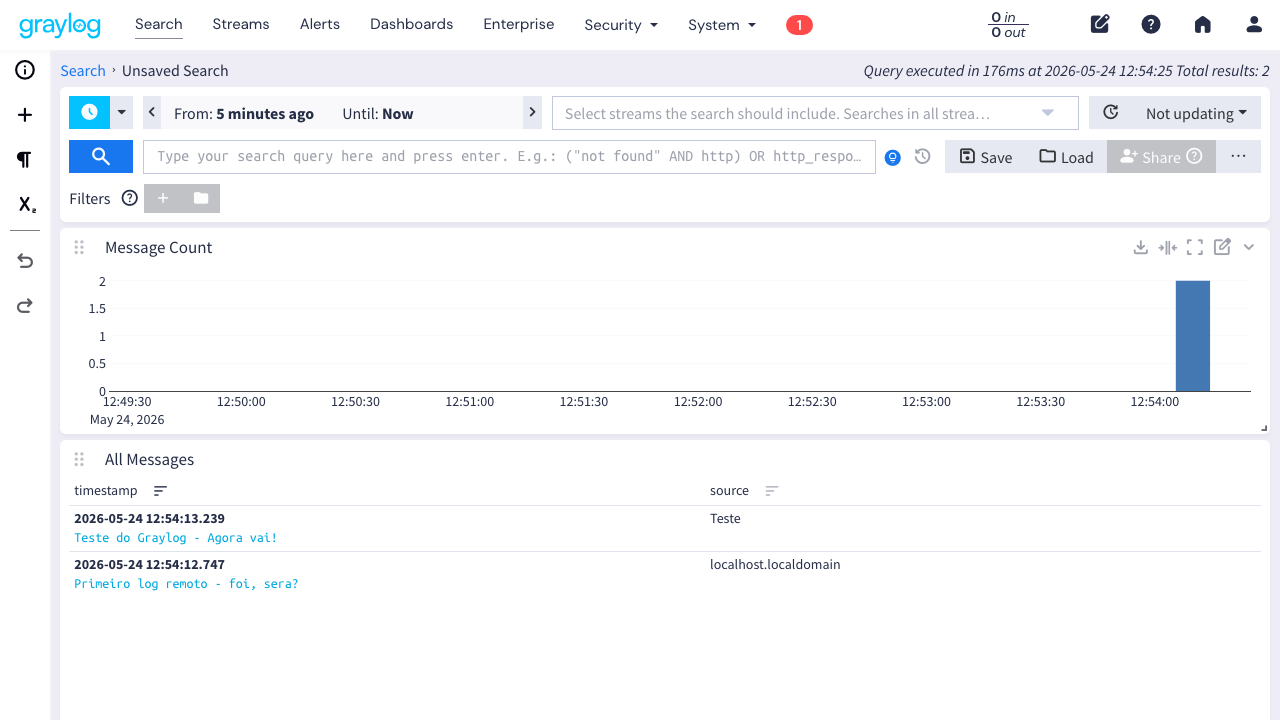
Checklist: tudo funcionando?
Antes de seguir, confirma esses três pontos:
- Containers rodando:
sudo podman psmostra mongodb, opensearch e graylog com status “Up” - Input ativo: Na página System > Inputs, o botão ao lado do input diz “Stop input” (não “Start input”)
- Logs chegando: A página Search mostra as mensagens de teste que você enviou
Se algum desses falhou, revise o passo correspondente antes de continuar.
Considerações de segurança (não ignore)
Antes de sair conectando tudo nesse servidor, alguns pontos importantes:
- Firewall: Só libere as portas pra IPs que você conhece. Não deixe aberto pra internet.
Fedora/RHEL (firewalld):
# Interface web (só pra sua máquina de administração)
sudo firewall-cmd --add-port=9000/tcp --permanent
# Recebimento de logs (só pra rede interna)
sudo firewall-cmd --add-port=1514/udp --permanent
sudo firewall-cmd --add-port=1514/tcp --permanent
sudo firewall-cmd --reloadPra restringir por IP ou rede de origem, usamos rich rules:
# Liberar porta 1514 apenas para a rede 192.168.1.0/24
sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="192.168.1.0/24" port port="1514" protocol="udp" accept'
sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="192.168.1.0/24" port port="1514" protocol="tcp" accept'
# Ou para um IP específico
sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="192.168.1.50" port port="9000" protocol="tcp" accept'
sudo firewall-cmd --reloadUbuntu/Debian (ufw):
# Interface web
sudo ufw allow 9000/tcp
# Recebimento de logs
sudo ufw allow 1514/udp
sudo ufw allow 1514/tcp
# Ou restringindo por rede de origem
sudo ufw allow from 192.168.1.0/24 to any port 1514 proto udp
sudo ufw allow from 192.168.1.0/24 to any port 1514 proto tcp
sudo ufw allow from 192.168.1.50 to any port 9000 proto tcp-
Rede Separada: Idealmente, logs trafegam numa VLAN de gerência, não na mesma rede dos usuários.
-
TLS: Pra ambientes de produção, configure inputs com TLS. Log em texto puro atravessando a rede não é ideal.
-
Backup: Aqueles volumes do compose são seus dados. Tenha uma estratégia de backup.
-
Rotação de índices: O OpenSearch vai acumulando dados e em algum momento o disco enche. O Graylog cuida disso pra você, mas vale conferir as configurações padrão em System > Indices. Lá você define quantos índices manter e quando rotacionar. Num lab com 64GB de disco, o padrão costuma dar conta. Em produção, ajuste conforme o volume de logs que você recebe.
Não precisa fazer tudo isso agora se é só um lab. Mas mantém na cabeça pra quando for pra produção.
Iniciando no boot
Um servidor de logs que não sobe sozinho depois de um reboot não serve pra muita coisa. Pra garantir que o Graylog inicie automaticamente, vamos criar um serviço systemd.
Primeiro, precisamos mover os arquivos para um local definitivo:
sudo mkdir -p /opt/graylog
sudo cp compose.yaml .env /opt/graylog/O repositório inclui um arquivo graylog.service pronto. Basta copiá-lo para o systemd:
sudo cp graylog.service /etc/systemd/system/
sudo systemctl daemon-reload
sudo systemctl enable graylog.serviceO conteúdo do serviço é simples:
[Unit]
Description=Graylog Stack (Graylog + OpenSearch + MongoDB)
After=network-online.target
Wants=network-online.target
[Service]
Type=oneshot
RemainAfterExit=yes
WorkingDirectory=/opt/graylog
ExecStart=/usr/bin/podman-compose up -d
ExecStop=/usr/bin/podman-compose down
TimeoutStartSec=300
[Install]
WantedBy=multi-user.targetA partir de agora, o stack sobe automaticamente no boot. Dá pra controlar manualmente também:
sudo systemctl start graylog # Inicia
sudo systemctl stop graylog # Para
sudo systemctl status graylog # Verifica statusConclusão
Temos agora um servidor central de logs funcionando. Um “vórtice” que engole tudo que mandarem pra ele e deixa a gente pesquisar depois.
Lembra do cenário do início? Disco encheu, máquina reiniciou, log sumiu. Isso não acontece mais. Os logs estão saindo das máquinas em tempo real, morando num lugar separado, com disco próprio e backup (você vai fazer backup, né?).
E de quebra, se algum dia um invasor ganhar root numa máquina e apagar o /var/log/… os logs já foram. Estão seguros em outro lugar.
O próximo passo
No próximo artigo, vamos voltar àquele tema de auditoria que mencionei. Vamos configurar nossos servidores Linux para enviar sessões completas de terminal, tipo um “vídeo em texto” de tudo que foi digitado, direto pra esse Graylog.
É uma evolução do velho rootsh, mas dessa vez feita do jeito certo: com os logs saindo da máquina em tempo real, antes que alguém possa apagar.
Até lá, vale a pena deixar esse Graylog rodando e ir explorando a interface, clicar nas coisas, fuçar os menus. Quando a gente começar a mandar log de verdade, você já vai estar em casa.
Este artigo faz parte de uma série sobre auditoria em ambientes Linux. Acompanhe os próximos para ver como transformar essa base em um sistema completo de monitoramento e resposta a incidentes.



Comentários
Comentários fechados para visitantes. Entre ou registre-se para comentar.