
Série Firecracker:
- Parte 01: Firecracker
- Parte 02: Construindo um nano-Lambda
- Parte 03: Redes no Firecracker
- Parte 04: Snapshots (você está aqui)
- Parte 05: Firecracker em produção
Nos artigos anteriores, construímos um nano-Lambda que gera QR codes e valida URLs. Funciona bem, roda em menos de 2 segundos. Mas e se a gente quisesse algo mais pesado? Um classificador de spam com machine learning, por exemplo?
Aí a coisa complica. Bibliotecas como scikit-learn demoram segundos só pra carregar. Cada execução do nano-Lambda vira uma espera de 7-8 segundos olhando pro terminal. Tenta ficar oito segundos olhando pra uma tela sem piscar. É uma eternidade. Se você rodar isso 10 vezes pra debugar, já perdeu mais de um minuto de vida olhando pro nada.
O problema é que a gente tá “ligando o computador” toda vez. Boot do kernel, init do sistema, import de bibliotecas pesadas… tudo do zero, a cada requisição. É como se você desligasse e ligasse seu notebook toda vez que quisesse abrir uma nova aba do Chrome.
A AWS não faz isso. Ela usa uma técnica chamada snapshot: tira uma “foto” da VM já pronta e restaura essa foto instantaneamente quando precisa. É hibernação turbinada — você clona um computador que já está ligado, com todos os programas abertos, e ele acorda sem saber que foi copiado.
Hoje a gente implementa isso.
TL;DR — O que você vai conseguir:
Métrica Antes Depois Tempo de inicialização ~7-8s ~300ms Speedup — ~25x Custo CPU (boot completo) Storage (512MB)
O problema: cold start pesado
Olha só onde o tempo tá indo. Quando a gente roda o classificador de spam com scikit-learn, dá pra ver exatamente o que tá demorando:
| Etapa | Tempo |
|---|---|
| Preparar ambiente (copiar rootfs 512MB) | ~2.5s |
| Iniciar Firecracker + socket | ~0.6s |
| Boot do kernel | ~0.1s |
| Init do Alpine | ~0.2s |
| Import do scikit-learn | ~3.5s |
| Treinar modelo | ~0.01s |
| Classificar texto | ~0.001s |
Olha o culpado aí. O import sklearn. Sozinho, ele come mais de 3 segundos. É um gordinho: carrega numpy, scipy, binários em C… É muita coisa pra arrastar do disco pra memória toda vez que a gente quer classificar uma frase simples.
A sacada é: e se a gente tirasse uma foto da VM depois que o scikit-learn já tá carregado? Economizaria esses 3+ segundos em toda execução subsequente.
A solução: snapshots
É exatamente o que acontece quando você fecha a tampa do notebook e ele hiberna. O sistema salva tudo no disco e desliga. Quando você abre, o Word e o Chrome estão lá, na mesma página, sem ter que carregar o Windows do zero. A VM nem sabe que foi “desligada” — pra ela, foi um cochilo instantâneo.
Um snapshot do Firecracker captura dois arquivos:
- Memória da VM (
vm_mem): Todo o conteúdo da RAM — código carregado, variáveis, estado dos processos - Estado da CPU (
vm_state): Registradores, program counter, estado da MMU
Com esses dois arquivos, você pode restaurar a VM exatamente no ponto onde ela estava. Não precisa fazer boot, não precisa carregar bibliotecas, não precisa inicializar nada. A VM simplesmente “acorda” pronta pra trabalhar.
O fluxo
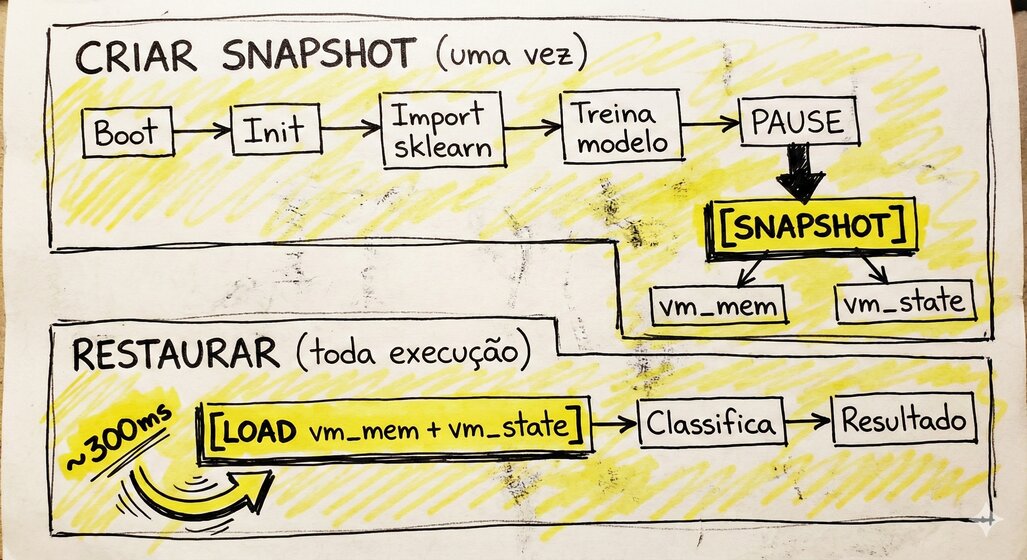
A primeira execução ainda é lenta (precisa criar o snapshot). Mas todas as seguintes pulam direto pro ponto onde a VM está pronta.
Nota: No nosso exemplo didático, a VM acorda num loop infinito de
sleep. Numa aplicação real, ela acordaria pronta pra ouvir um socket e processar requisições imediatamente.
Preparando o terreno
Se você acompanhou os artigos anteriores, já deve ter:
- Firecracker funcionando (artigo 1)
- nano-Lambda rodando (artigo 2)
- Python 3 com
requests-unixsocketinstalado
Agora a gente precisa de um rootfs com scikit-learn pra ter um cold start bem gordo e visível.
Um conselho de quem já travou a máquina fazendo isso: libera espaço. Sério. O rootfs tem 512MB, o snapshot mais 512MB… quando você vê, seu
/tmplotou e o Linux começa a reclamar. Garante pelo menos 1GB livre antes de rodar o script pra não passar raiva.
# build-rootfs-sklearn.sh
#!/bin/bash
set -e
ROOTFS="rootfs-sklearn.ext4"
SIZE_MB=512
MOUNT_POINT="/tmp/rootfs-mount"
echo "Criando rootfs com scikit-learn"
dd if=/dev/zero of=$ROOTFS bs=1M count=$SIZE_MB
mkfs.ext4 -F $ROOTFS
mkdir -p $MOUNT_POINT
sudo mount $ROOTFS $MOUNT_POINT
# Instala Alpine com sklearn
sudo podman run --rm -v $MOUNT_POINT:/rootfs alpine:3.21 sh -c '
apk add --root /rootfs --initdb \
alpine-base openrc \
python3 py3-pip py3-numpy py3-scikit-learn py3-joblib
'
sudo mkdir -p $MOUNT_POINT/functions
sudo mkdir -p $MOUNT_POINT/model
# Cria init.sh que será usado para snapshot
sudo tee $MOUNT_POINT/init.sh > /dev/null << 'INIT'
#!/bin/sh
mount -t proc proc /proc
mount -t sysfs sysfs /sys
mount -t devtmpfs devtmpfs /dev 2>/dev/null || true
# Carrega sklearn e treina modelo
python3 << 'PYEOF'
import time
start = time.time()
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
print(f"[TIMING] sklearn importado em {time.time()-start:.3f}s")
# Dados de treino
texts = [
"ganhe dinheiro rapido agora",
"voce ganhou um premio clique aqui",
"oferta imperdivel so hoje",
"reuniao amanha as 10h",
"relatorio do projeto em anexo",
"ola tudo bem com voce"
] * 10
labels = [1, 1, 1, 0, 0, 0] * 10 # 1=spam, 0=ham
# Treina
model = Pipeline([
("tfidf", TfidfVectorizer()),
("clf", MultinomialNB())
])
model.fit(texts, labels)
print("[READY] Modelo treinado - VM pronta para snapshot")
PYEOF
# Sinaliza que está pronto e aguarda
echo "SNAPSHOT_READY"
while true; do sleep 1; done
INIT
sudo chmod +x $MOUNT_POINT/init.sh
sudo umount $MOUNT_POINT
rmdir $MOUNT_POINT
echo "=== Rootfs criado: $ROOTFS ==="Execute o script (precisa de root por causa do mount):
chmod +x build-rootfs-sklearn.sh
sudo ./build-rootfs-sklearn.shO momento certo do snapshot
Aqui tem um “pulo do gato” que se você errar, nada funciona. O timing.
Se pausar cedo demais, o scikit-learn não carregou. O snapshot vai capturar a VM no meio do import, e você não ganha nada. Se pausar tarde, perdeu tempo. A gente precisa que a VM grite “Tô pronta!” antes de congelar.
A solução é um “aperto de mão” entre a VM e o host:
- A VM carrega tudo que precisa
- A VM imprime um marcador:
SNAPSHOT_READY - O host monitora o output da VM
- Quando vê o marcador, pausa e tira o snapshot
Esse padrão é tão comum que vale destacar:
# Dentro da VM (init.sh)
print("SNAPSHOT_READY") # Sinaliza pro host
# No host (orquestrador)
while True:
output = read_vm_console()
if "SNAPSHOT_READY" in output:
pause_vm()
create_snapshot()
breakSem esse handshake, você fica no escuro — pode acabar capturando uma VM ainda em inicialização.
Implementando o teste
Vamos criar um script que:
- Mede o cold start completo
- Cria um snapshot
- Mede o tempo de restore
#!/usr/bin/env python3
"""
test-snapshot.py - Compara cold start vs restore no Firecracker
"""
import subprocess
import requests_unixsocket
import time
import shutil
import tempfile
import os
import sys
FIRECRACKER_BIN = "./firecracker"
KERNEL_PATH = "./vmlinux.bin"
ROOTFS_TEMPLATE = "./rootfs-sklearn.ext4"
SOCKET_PATH = "/tmp/fc-snapshot.socket"
SNAPSHOT_PATH = "/tmp/fc-snapshot"
MEM_FILE = f"{SNAPSHOT_PATH}/vm_mem"
STATE_FILE = f"{SNAPSHOT_PATH}/vm_state"
def api_url(path):
encoded = SOCKET_PATH.replace("/", "%2F")
return f"http+unix://{encoded}{path}"
def call_api(method, path, data=None):
session = requests_unixsocket.Session()
url = api_url(path)
if method == "PUT":
resp = session.put(url, json=data)
elif method == "PATCH":
resp = session.patch(url, json=data)
elif method == "GET":
resp = session.get(url)
if resp.status_code >= 400:
raise Exception(f"API error: {resp.status_code} - {resp.text}")
return resp
def cleanup():
"""Limpa processos e arquivos anteriores."""
subprocess.run(["pkill", "-9", "firecracker"], capture_output=True)
time.sleep(0.5)
for path in [SOCKET_PATH]:
if os.path.exists(path):
os.remove(path)
if os.path.exists(SNAPSHOT_PATH):
shutil.rmtree(SNAPSHOT_PATH)
def start_firecracker(log_file=None):
"""Inicia o processo Firecracker."""
if os.path.exists(SOCKET_PATH):
os.remove(SOCKET_PATH)
stdout = open(log_file, "w") if log_file else subprocess.PIPE
proc = subprocess.Popen(
[FIRECRACKER_BIN, "--api-sock", SOCKET_PATH],
stdout=stdout,
stderr=subprocess.STDOUT
)
for _ in range(50):
if os.path.exists(SOCKET_PATH):
break
time.sleep(0.1)
time.sleep(0.2)
return proc
def configure_vm(rootfs_path):
"""Configura kernel, rootfs e recursos."""
call_api("PUT", "/boot-source", {
"kernel_image_path": KERNEL_PATH,
"boot_args": "console=ttyS0 reboot=k panic=1 pci=off init=/init.sh"
})
call_api("PUT", "/drives/rootfs", {
"drive_id": "rootfs",
"path_on_host": rootfs_path,
"is_root_device": True,
"is_read_only": False
})
call_api("PUT", "/machine-config", {
"vcpu_count": 1,
"mem_size_mib": 256
})
def wait_for_ready(log_file, timeout=30):
"""Aguarda VM sinalizar que está pronta."""
start = time.time()
while time.time() - start < timeout:
if os.path.exists(log_file):
with open(log_file, "r") as f:
if "SNAPSHOT_READY" in f.read():
return True
time.sleep(0.1)
return False
def main():
if os.geteuid() != 0:
print("Execute como root: sudo python3 test-snapshot.py")
sys.exit(1)
print("=" * 60)
print("Teste de Snapshot/Restore do Firecracker")
print("=" * 60)
cleanup()
# PARTE 1: Cold Start
print("\n[1] COLD START")
print("-" * 40)
cold_start = time.time()
temp_rootfs = tempfile.NamedTemporaryFile(suffix=".ext4", delete=False).name
shutil.copy(ROOTFS_TEMPLATE, temp_rootfs)
print(f" Rootfs copiado ({time.time() - cold_start:.3f}s)")
# Inicia Firecracker
log_file = "/tmp/fc-boot.log"
fc_proc = start_firecracker(log_file)
print(f" Firecracker iniciado ({time.time() - cold_start:.3f}s)")
# Configura VM
configure_vm(temp_rootfs)
print(f" VM configurada ({time.time() - cold_start:.3f}s)")
# Inicia VM
call_api("PUT", "/actions", {"action_type": "InstanceStart"})
print(" VM iniciada - aguardando SNAPSHOT_READY...")
# Aguarda sklearn carregar
if not wait_for_ready(log_file):
print(" ERRO: Timeout esperando VM ficar pronta")
return
cold_time = time.time() - cold_start
print(f"\n >>> COLD START: {cold_time:.3f}s")
# Mostra timing do sklearn
with open(log_file, "r") as f:
for line in f:
if "[TIMING]" in line or "[READY]" in line:
print(f" {line.strip()}")
# PARTE 2: Criar Snapshot
print("\n[2] CRIANDO SNAPSHOT")
print("-" * 40)
snap_start = time.time()
# Pausa VM
call_api("PATCH", "/vm", {"state": "Paused"})
print(f" VM pausada ({time.time() - snap_start:.3f}s)")
# Cria snapshot
os.makedirs(SNAPSHOT_PATH, exist_ok=True)
call_api("PUT", "/snapshot/create", {
"snapshot_type": "Full",
"snapshot_path": STATE_FILE,
"mem_file_path": MEM_FILE
})
snap_time = time.time() - snap_start
print(f" Snapshot criado ({snap_time:.3f}s)")
# Mostra tamanhos
mem_size = os.path.getsize(MEM_FILE) / (1024 * 1024)
state_size = os.path.getsize(STATE_FILE) / 1024
print(f" Arquivos: memoria={mem_size:.0f}MB, estado={state_size:.0f}KB")
# Para VM original
fc_proc.terminate()
fc_proc.wait()
if os.path.exists(SOCKET_PATH):
os.remove(SOCKET_PATH)
# PARTE 3: Restore
print("\n[3] RESTORE")
print("-" * 40)
restore_start = time.time()
# Novo Firecracker
fc_proc2 = start_firecracker()
print(f" Firecracker iniciado ({time.time() - restore_start:.3f}s)")
# Carrega snapshot
call_api("PUT", "/snapshot/load", {
"snapshot_path": STATE_FILE,
"mem_backend": {
"backend_type": "File",
"backend_path": MEM_FILE
},
"enable_diff_snapshots": False,
"resume_vm": True
})
restore_time = time.time() - restore_start
print(f"\n >>> RESTORE: {restore_time:.3f}s")
# RESUMO
print("\n" + "=" * 60)
print("RESULTADOS")
print("=" * 60)
print(f" Cold Start: {cold_time:.3f}s")
print(f" Criar Snapshot: {snap_time:.3f}s")
print(f" Restore: {restore_time:.3f}s")
print()
print(f" Speedup: {cold_time/restore_time:.1f}x mais rapido")
print(f" Economia: {cold_time - restore_time:.3f}s por execucao")
print("=" * 60)
# Cleanup
fc_proc2.terminate()
fc_proc2.wait()
os.remove(temp_rootfs)
if __name__ == "__main__":
main()Executando o teste
sudo python3 test-snapshot.pyResultado no meu ambiente:
============================================================
Teste de Snapshot/Restore do Firecracker
============================================================
NOTA: Esta VM esta isolada (sem rede).
Para acesso a internet, veja o artigo sobre networking.
[1] COLD START (boot + sklearn)
----------------------------------------
Rootfs preparado (1.048s)
Firecracker iniciado (1.355s)
VM configurada (1.401s)
VM iniciada - aguardando SNAPSHOT_READY...
>>> COLD START TOTAL: 7.796s
[2] CRIANDO SNAPSHOT
----------------------------------------
VM pausada (0.005s)
Snapshot criado (0.645s)
Memoria: 512.0 MB | Estado: 14.6 KB
VM original terminada
[3] RESTORE DO SNAPSHOT
----------------------------------------
Firecracker iniciado (0.301s)
>>> RESTORE TOTAL: 0.309s
============================================================
RESULTADOS
============================================================
Cold Start: 7.796s
Criar Snapshot: 0.645s
Restore: 0.309s
Speedup: 25.2x mais rapido
Economia: 7.488s por execucao
============================================================~300 milissegundos. Piscou, perdeu. Saímos de uma espera de cafézinho (~8s) para algo instantâneo. É mais de 25x mais rápido. A sensação de usar muda da água pro vinho.
Por que isso importa
Não parece muito no papel. Mas na prática, a diferença é brutal:
- ~8 segundos: O usuário clica, vê uma tela carregando, tem tempo de pensar “travou?”, considera fechar a aba. É uma eternidade em interações web.
- ~300 milissegundos: Imperceptível. Qualquer coisa abaixo de 300-400ms é sentida como “instantânea”. O usuário nem percebe que esperou.
O trade-off: CPU por Storage
Olha os tamanhos dos arquivos de snapshot:
- Memória: 512MB (toda a RAM da VM)
- Estado: ~15KB (registradores, program counter)
Você está trocando ~8 segundos de CPU por 512MB de disco. Em nuvem, esse trade-off quase sempre compensa — armazenamento é barato, tempo de computação e paciência do usuário são caros.
Nota técnica: Os ~300ms incluem o tempo de iniciar o processo Firecracker do zero (~300ms). O restore da memória em si leva poucos milissegundos. Orquestradores de alta performance (como o Lambda por baixo dos panos) mantêm processos “pré-aquecidos”, reduzindo o tempo total para 20-50ms.
O que está acontecendo por baixo
Quando você chama /snapshot/create, o Firecracker:
- Pausa a vCPU — para a execução do guest no ponto exato
- Serializa registradores — salva PC, SP, flags, todos os registradores
- Dumpa a memória — escreve toda a RAM guest num arquivo
- Salva estado de dispositivos — serial, block devices, etc
No restore:
- Aloca memória — reserva RAM pro guest
- Carrega dump — mapeia o arquivo de memória
- Restaura registradores — coloca CPU virtual no estado salvo
- Resume — execução continua exatamente onde parou
A VM literalmente “acorda” no meio de um sleep(1). Ela não sabe que foi pausada, serializada pra disco, e restaurada numa instância nova do Firecracker. Pra ela, foi um cochilo instantâneo.
Escala horizontal: múltiplas VMs do mesmo snapshot
E aqui que a coisa fica interessante de verdade. Um snapshot pode ser usado pra criar múltiplas VMs ao mesmo tempo. Cada uma começa no mesmo estado, mas evolui independentemente.
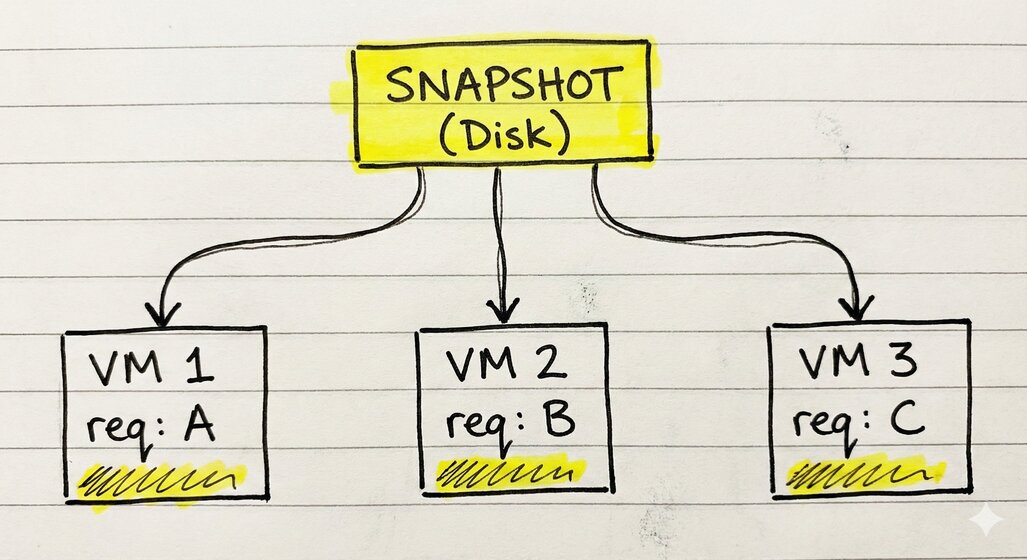
Isso é exatamente o que serviços como Lambda fazem pra escalar. Um snapshot “dourado” com o runtime pronto, e dezenas de VMs sendo restauradas dele conforme as requisições chegam.
O custo de inicialização pesado (carregar bibliotecas, treinar modelo) é pago uma vez. Todas as execuções subsequentes pagam só o custo do restore.
Dica de ouro pra produção: Copy-on-Write. Sabe aquele arquivo de 512MB da memória? Você não precisa copiar ele pra cada nova VM. Você pode fazer 100 VMs lerem o mesmo arquivo ao mesmo tempo. O Linux cuida da mágica — só copia as páginas que cada VM modifica. Resultado? Você sobe um exército de Lambdas gastando quase a mesma RAM de um só.
Quando usar snapshots
Snapshots fazem mais sentido quando:
- Inicialização é cara: Carregar ML models, conectar em bancos, aquecer caches
- Execuções são frequentes: O custo do snapshot se dilui em muitas restaurações
- Estado inicial é previsível: Você pode criar um snapshot “genérico” que serve pra várias requisições
Não faz sentido quando:
- Inicialização é rápida: Se sua função carrega em 50ms, o overhead do snapshot não compensa
- Estado varia muito: Se cada execução precisa de configuração diferente, um snapshot genérico não ajuda
- Execuções são raras: O snapshot fica obsoleto, você gasta tempo criando algo que mal usa
Conclusão
Pronto. Agora você sabe como o Lambda consegue responder em milissegundos mesmo rodando VMs completas por baixo. Não é mágica — é engenharia cuidadosa com snapshots.
Se você notou que essa VM está isolada (sem rede), a Parte 03 já cobre isso: TAP devices, NAT e como dar acesso à internet pra sua microVM.
Com snapshots + networking, você tem quase todas as peças. Falta uma: em produção, ninguém fica rodando scripts Python na mão. No próximo artigo, a gente daemoniza as microVMs com systemd — pra elas iniciarem no boot, reiniciarem se morrerem, e se comportarem como serviços de verdade.
Arquivos deste artigo:
build-rootfs-sklearn.sh— Script pra criar rootfs com scikit-learntest-snapshot.py— Teste comparando cold start vs restore
| Números reais medidos: | Métrica | Valor |
|---|---|---|
| Cold Start | ~8s | |
| Restore | ~300ms | |
| Speedup | ~25x | |
| Tamanho memória | 512MB | |
| Tamanho estado | ~15KB |



Comentários
Comentários fechados para visitantes. Entre ou registre-se para comentar.