
Série CSI do Linux
- Parte 01: Montando seu servidor de logs com Graylog
- Parte 02: Gravando sessões de terminal com tlog
- Parte 03: Transformando logs em alertas Graylog (você está aqui)
Nos dois artigos anteriores, montamos a infraestrutura: um servidor central de logs com Graylog e gravação de sessões de terminal com tlog. Os dados estão chegando, indexados, pesquisáveis. Mas… você vai ficar olhando pro Graylog o dia todo esperando algo acontecer? É aqui que entram os alertas Graylog, o sistema que transforma dados passivos em detecção ativa.
Logs sem alertas são como câmeras de segurança sem ninguém assistindo. Você só descobre que algo aconteceu quando já é tarde demais, e aí volta pra revisar as gravações. Não é assim que queremos operar.
Neste artigo, vamos transformar o Graylog de um repositório passivo em um sistema de detecção ativa. Vamos criar alertas que te avisam quando algo suspeito acontece, antes que você precise procurar.
Conceitos fundamentais do sistema de alertas
Este tutorial foca na engine de eventos do Graylog 7.x. Se você usa a versão 5 ou anterior, a interface de alertas é completamente diferente (era chamada de “Alerts & Callbacks”). Os conceitos são parecidos, mas as telas e opções mudaram bastante.
Antes de sair criando alertas, vale entender como o Graylog organiza esse sistema. A arquitetura mudou bastante nas versões recentes, então mesmo que você já tenha usado alertas em versões anteriores, algumas coisas podem parecer diferentes.
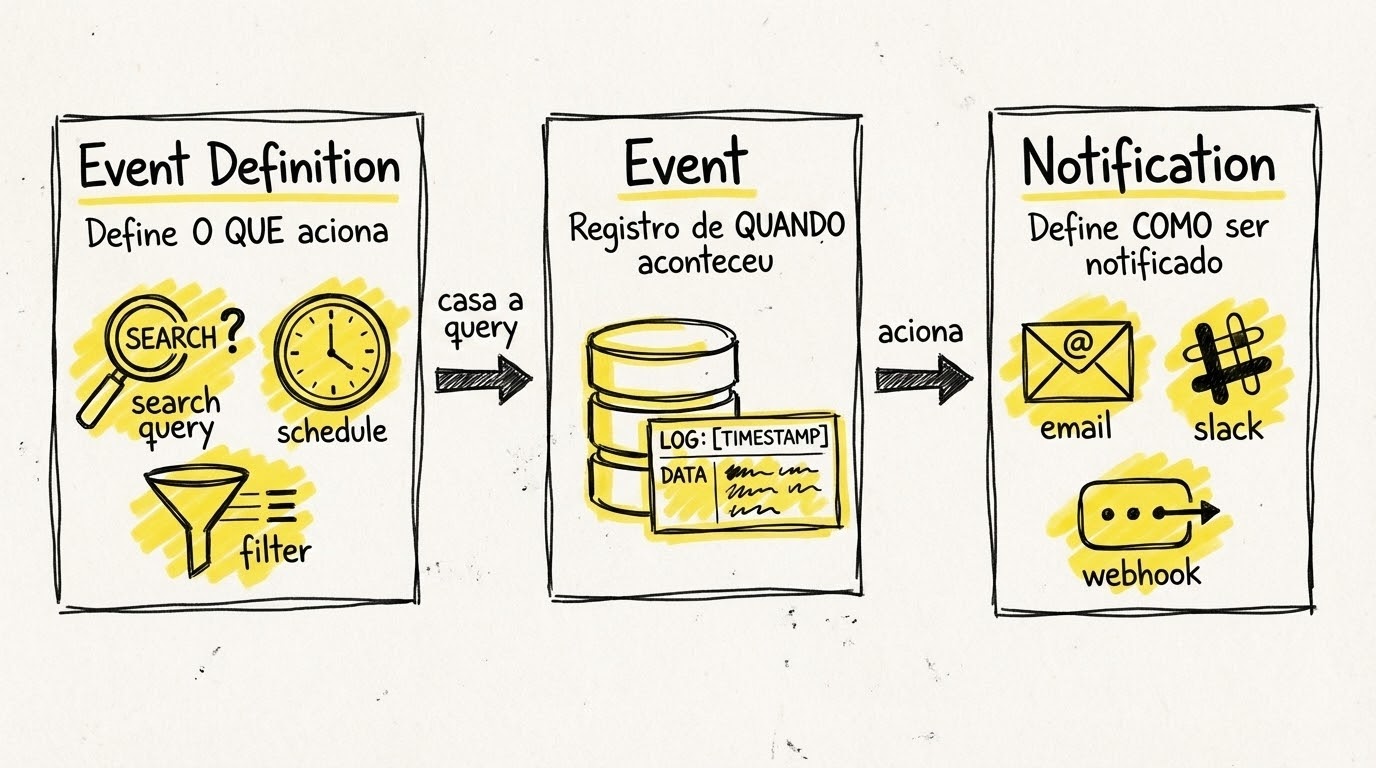
Do que é feito um alerta
O sistema de alertas do Graylog 7.x é composto por três peças principais que trabalham juntas:
Event Definition é a regra que define “o que” dispara o alerta. Aqui a gente configura a query de busca, as condições de disparo (uma mensagem específica apareceu? aconteceram mais de X eventos em Y minutos?), e quais campos extrair para incluir na notificação.
Notification é o “como” você será avisado. Pode ser email, Slack, webhook para um sistema externo, ou até mesmo uma ação customizada. Uma mesma notification pode ser reutilizada por várias event definitions. Por exemplo, você pode ter uma notification “Equipe de Segurança” que é acionada por diferentes tipos de alertas.
Event é o registro do que aconteceu quando a regra foi acionada. O Graylog mantém um histórico de todos os eventos gerados, permitindo que você investigue depois quais alertas dispararam, quando, e com quais dados.
Tipos de condições
O Graylog oferece três abordagens para definir quando um alerta deve disparar:
Filter & Aggregation é o tipo mais comum. Funciona assim: você define uma query (como faria numa busca normal) e depois escolhe uma condição:
-
Filter: Dispara sempre que uma mensagem corresponde à query. Exemplo:
application_name:sshd AND message:"session opened for user root"dispara cada vez que root logar via SSH. -
Aggregation: Dispara baseado em contagem ou estatísticas sobre as mensagens que correspondem à query. Exemplo: mais de 10 falhas de autenticação em 5 minutos, agrupadas por IP de origem.
Correlation combina múltiplos eventos em sequência temporal. Isso permite detectar padrões mais sofisticados, como “falha de login seguida de sucesso no mesmo IP em menos de 5 minutos”, o que pode indicar um brute force bem-sucedido.
Para este artigo, vamos focar em Filter e Aggregation, que cobrem a maioria dos casos de uso. Correlation merece um artigo próprio pela complexidade envolvida (spoiler: vem aí na Parte 04).
Configurando notificações
Antes de criar os alertas propriamente ditos, precisamos configurar como seremos avisados. Não adianta ter a regra perfeita se o aviso vai parar numa caixa de email que ninguém olha (quem nunca?).
Para enviar alertas por email, o Graylog precisa de um servidor SMTP configurado. Vamos adicionar as variáveis necessárias no nosso compose.yaml.
No arquivo .env que já temos do artigo anterior, adicionamos as configurações de email:
# Configurações de Email
GRAYLOG_TRANSPORT_EMAIL_ENABLED=true
GRAYLOG_TRANSPORT_EMAIL_HOSTNAME=smtp.seudominio.com.br
GRAYLOG_TRANSPORT_EMAIL_PORT=587
GRAYLOG_TRANSPORT_EMAIL_USE_AUTH=true
[email protected]
GRAYLOG_TRANSPORT_EMAIL_AUTH_PASSWORD=senha_do_email
GRAYLOG_TRANSPORT_EMAIL_USE_TLS=true
[email protected]
GRAYLOG_TRANSPORT_EMAIL_WEB_INTERFACE_URL=https://graylog.seudominio.com.brE no compose.yaml, garantimos que essas variáveis sejam passadas para o container do Graylog:
services:
graylog:
# ... configurações existentes ...
environment:
# ... variáveis existentes ...
- GRAYLOG_TRANSPORT_EMAIL_ENABLED=${GRAYLOG_TRANSPORT_EMAIL_ENABLED:-false}
- GRAYLOG_TRANSPORT_EMAIL_HOSTNAME=${GRAYLOG_TRANSPORT_EMAIL_HOSTNAME:-}
- GRAYLOG_TRANSPORT_EMAIL_PORT=${GRAYLOG_TRANSPORT_EMAIL_PORT:-587}
- GRAYLOG_TRANSPORT_EMAIL_USE_AUTH=${GRAYLOG_TRANSPORT_EMAIL_USE_AUTH:-true}
- GRAYLOG_TRANSPORT_EMAIL_AUTH_USERNAME=${GRAYLOG_TRANSPORT_EMAIL_AUTH_USERNAME:-}
- GRAYLOG_TRANSPORT_EMAIL_AUTH_PASSWORD=${GRAYLOG_TRANSPORT_EMAIL_AUTH_PASSWORD:-}
- GRAYLOG_TRANSPORT_EMAIL_USE_TLS=${GRAYLOG_TRANSPORT_EMAIL_USE_TLS:-true}
- GRAYLOG_TRANSPORT_EMAIL_FROM_EMAIL=${GRAYLOG_TRANSPORT_EMAIL_FROM_EMAIL:-}
- GRAYLOG_TRANSPORT_EMAIL_WEB_INTERFACE_URL=${GRAYLOG_TRANSPORT_EMAIL_WEB_INTERFACE_URL:-}Depois de atualizar os arquivos, aplique as mudanças recriando o container:
sudo podman-compose up -dpodman-compose restart, isso apenas para e inicia o container sem recarregar as variáveis de ambiente. O up -d recria o container com as novas configurações.
Agora podemos criar a notification de email na interface:
- Acesse Alerts > Notifications
- Clique em Create notification
- Escolha Email Notification como tipo
- Configure:
- Title: Equipe de Segurança
- Description: Notificação para incidentes de segurança
- Sender: [email protected] (ou deixe em branco para usar o padrão)
- Email Recipients: [email protected], [email protected]
- Email Subject:
Graylog Alert: ${event_definition_title} - Email Body: Vamos usar um template customizado (veja abaixo)
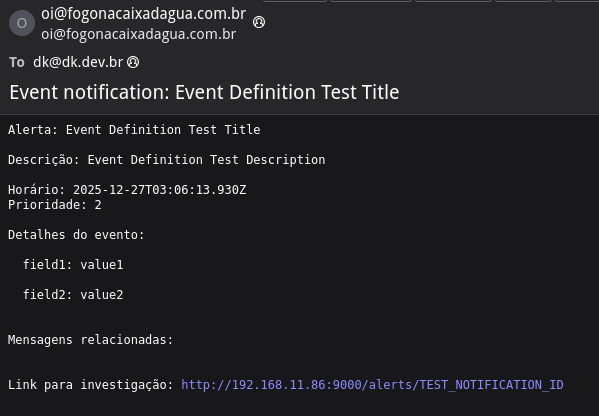
Para o corpo do email, um template útil:
Alerta: ${event_definition_title}
Descrição: ${event_definition_description}
Horário: ${event.timestamp}
Prioridade: ${event.priority}
Detalhes do evento:
${foreach event.fields field}
${field.key}: ${field.value}
${end}
Mensagens relacionadas:
${foreach backlog message}
Timestamp: ${message.timestamp}
Source: ${message.source}
Message: ${message.message}
${end}
Link para investigação: ${http_external_uri}alerts/${event.id}Clique em Test Notification para verificar se o email chega corretamente antes de salvar.
Slack / Discord / Teams
Webhooks são a forma universal de integrar o Graylog com plataformas de chat. O processo é similar para todas:
No Slack:
- Acesse a página de apps do Slack
- Crie um novo app ou use um existente
- Em Incoming Webhooks, ative e crie um webhook para o canal desejado
- Copie a URL do webhook (formato:
https://hooks.slack.com/services/T.../B.../xxx)
No Graylog:
- Alerts > Notifications > Create notification
- Tipo: HTTP Notification (para Slack) ou use plugins específicos se disponíveis
- URL: Cole a URL do webhook
- Configure o payload no formato esperado pelo Slack
Aqui vai um exemplo simplificado do payload:
{
"text": "*Alerta Graylog*: ${event_definition_title}",
"attachments": [{
"color": "danger",
"fields": [
{"title": "Descrição", "value": "${event_definition_description}", "short": false},
{"title": "Horário", "value": "${event.timestamp}", "short": true},
{"title": "Prioridade", "value": "${event.priority}", "short": true}
]
}]
}O payload completo com blocos interativos (botões, seções formatadas) está disponível no arquivo
slack-payload-completo.jsonno repositório do artigo.
Webhook genérico
Para integrar com sistemas de gerenciamento de incidentes como PagerDuty, Opsgenie, ou scripts customizados, usamos o HTTP Notification com o payload apropriado para cada serviço.
O Graylog envia um POST com Content-Type application/json. O payload padrão inclui:
{
"event_definition_id": "...",
"event_definition_title": "...",
"event_definition_description": "...",
"event": {
"id": "...",
"timestamp": "...",
"priority": 2,
"fields": { ... }
},
"backlog": [ ... ]
}Para PagerDuty, você precisa transformar esse payload no formato da Events API v2. Uma opção é usar um script intermediário ou o PagerDuty Integration Plugin do Graylog.
Alertas práticos de segurança
Agora vem a parte divertida. Vamos criar seis alertas que cobrem cenários reais de segurança, do mais simples ao mais elaborado.
Alerta 1: Login SSH como root
Em servidores bem configurados, ninguém deveria logar diretamente como root. Se isso acontece, ou é emergência (e deveria estar documentado) ou é um problema de segurança. A própria existência de logins root diretos já indica que as políticas de acesso precisam de revisão.
Implementação passo a passo:
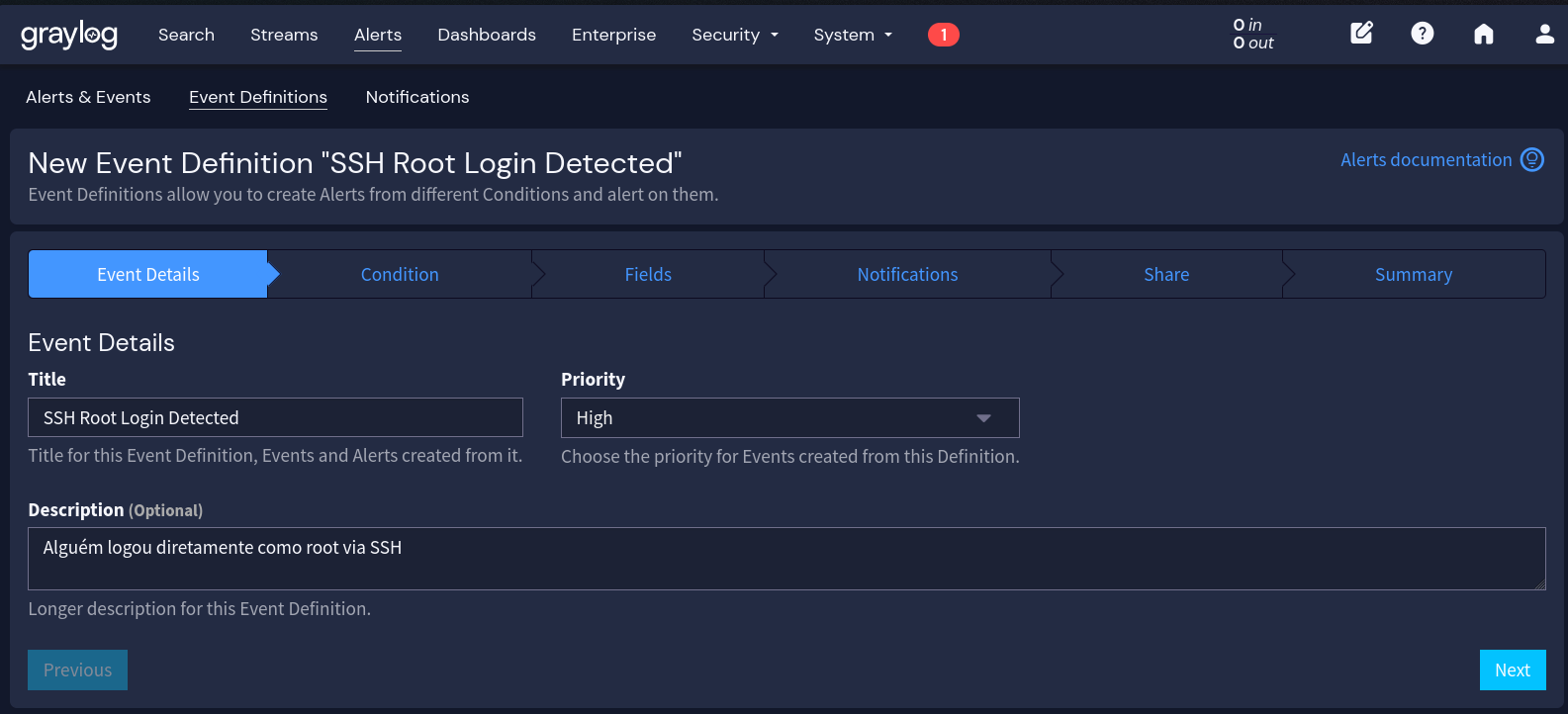
- Acesse Alerts > Event Definitions
- Clique em Create event definition
- Na aba Event Details:
- Title: SSH Root Login Detected
- Description: Alguém logou diretamente como root via SSH
- Priority: High
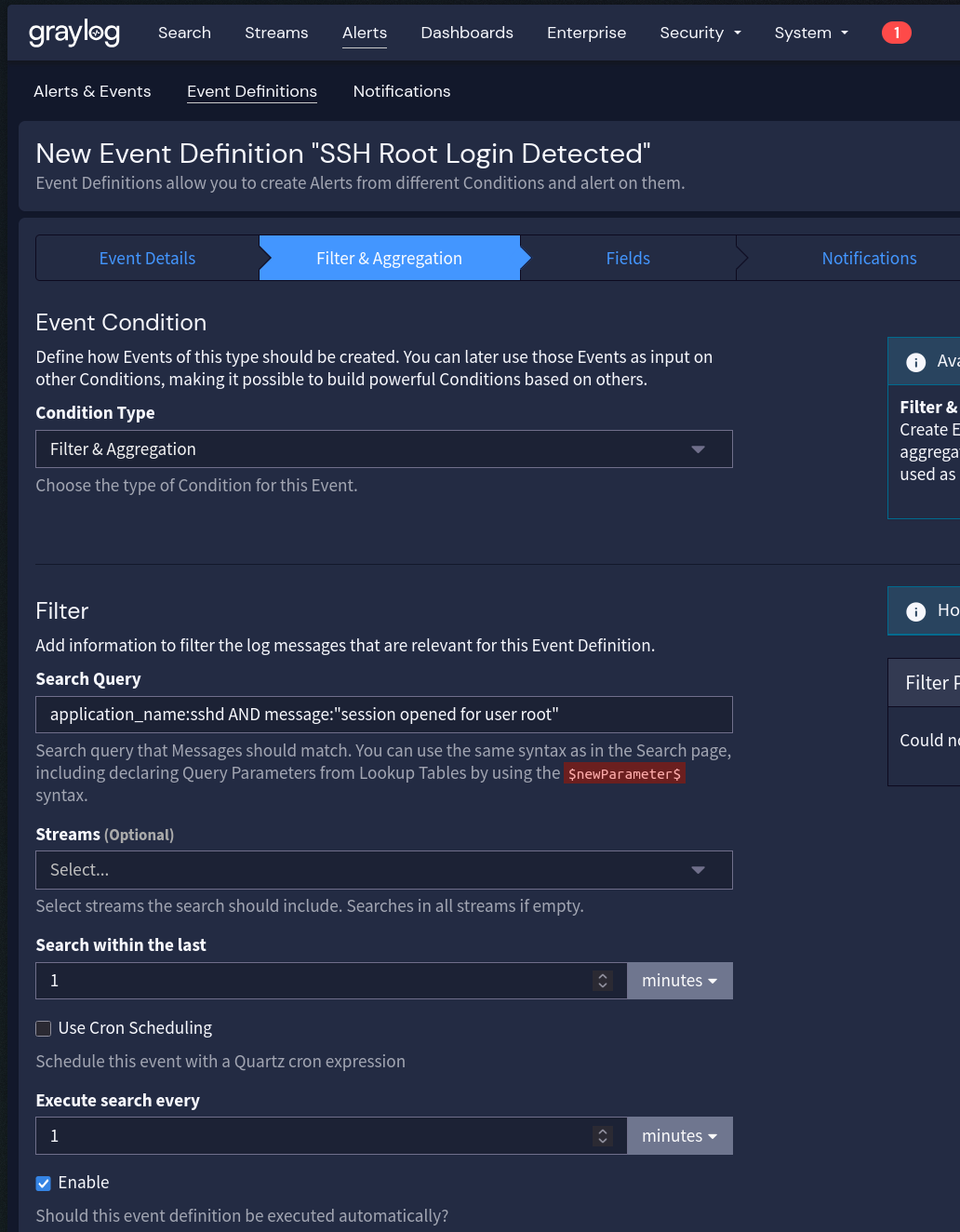
- Na aba Condition:
- Condition Type: Filter & Aggregation
- Search Query:
application_name:sshd AND message:"session opened for user root" - Search within: 1 minute
- Execute every: 1 minute
- Filter: crie um filtro se necessário para restringir a streams específicos
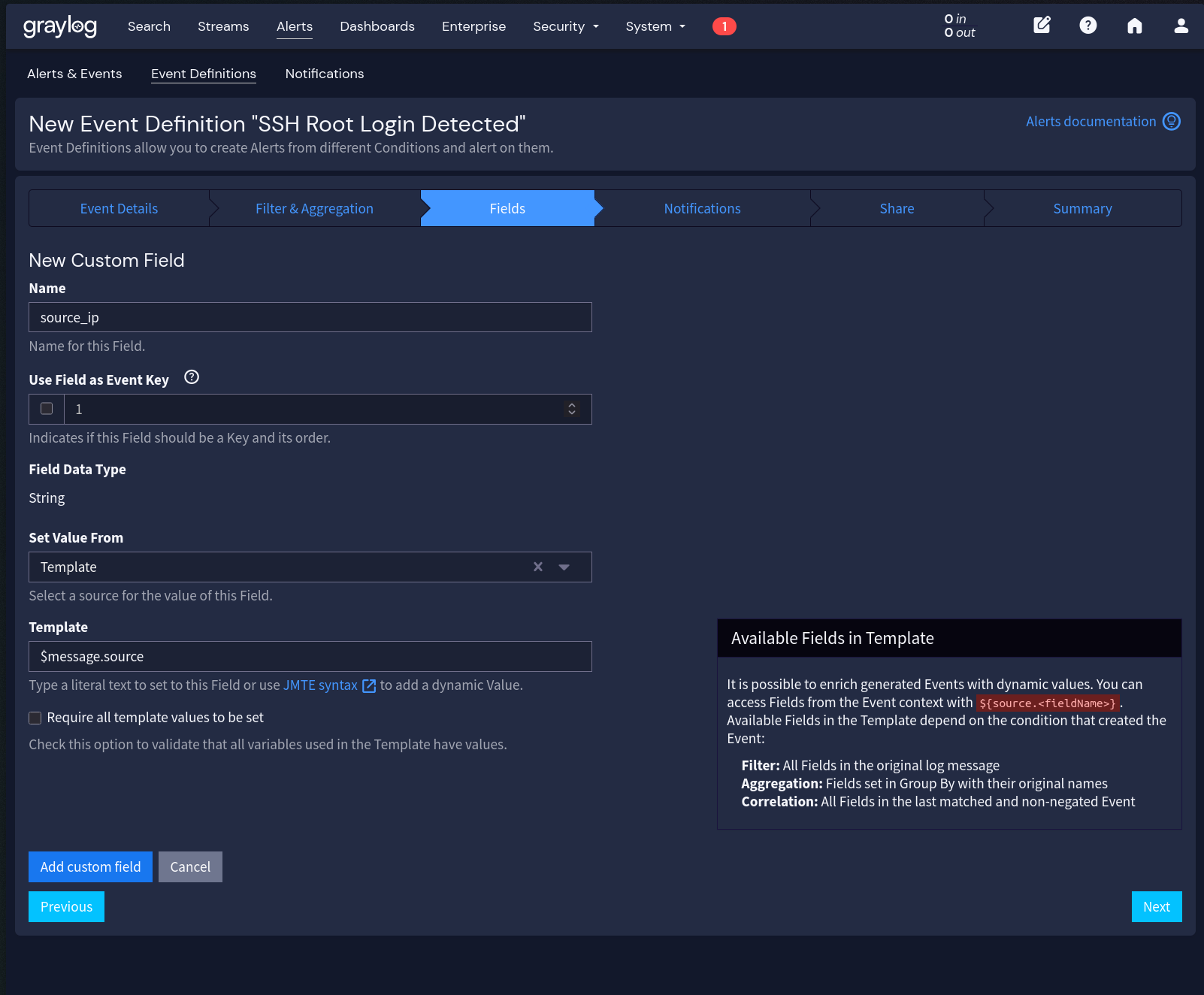
- Na aba Fields (campos a extrair para a notificação):
- Clique em Add Custom Field
- Name: source_ip
- Set Value From: Template
- Template: $message.source
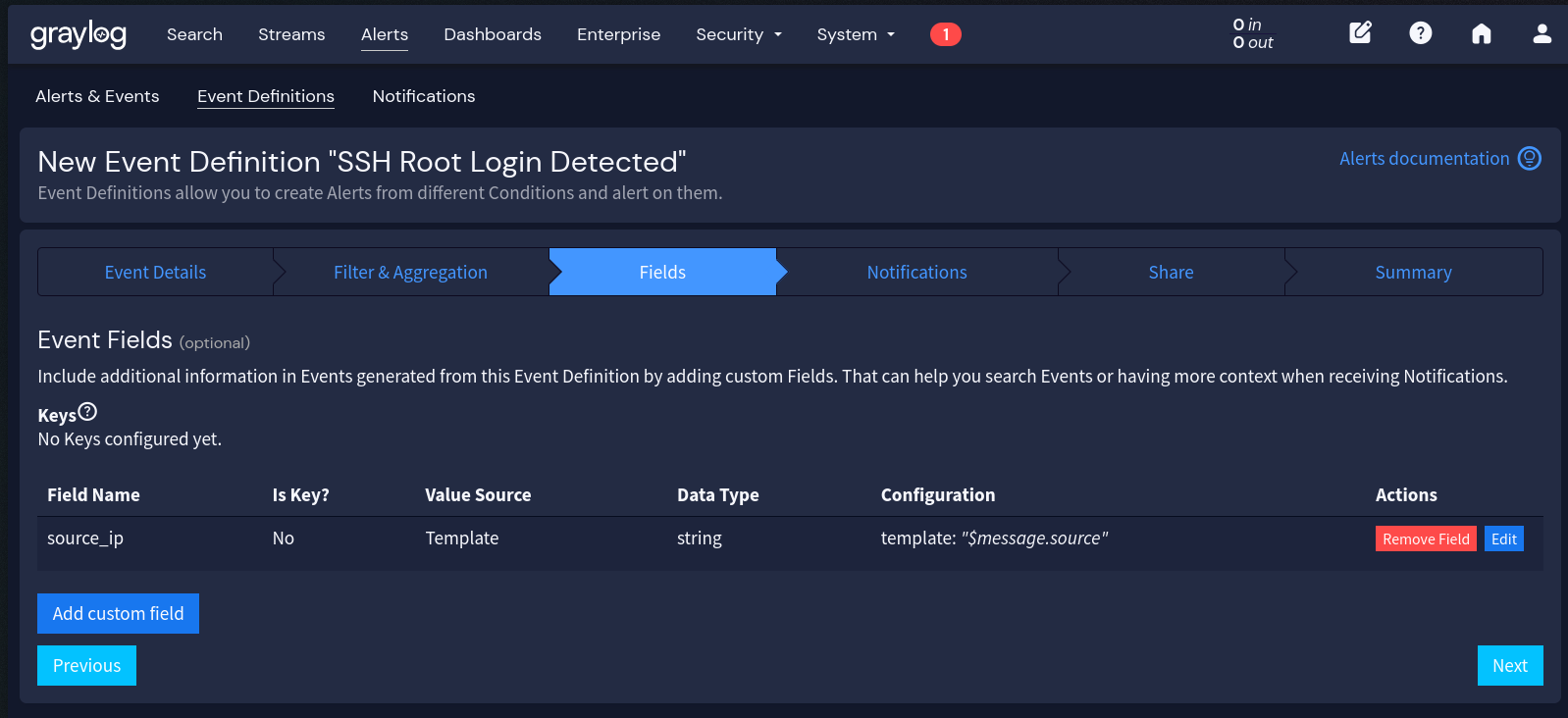
A partir daqui, vamos usar um formato resumido para os campos:
nome_do_campo <- template. O processo é sempre o mesmo: _Add Custom Field_ -> preencher Name > selecionar “_Template_” em Set Value From -> preencher o Template com o valor indicado.
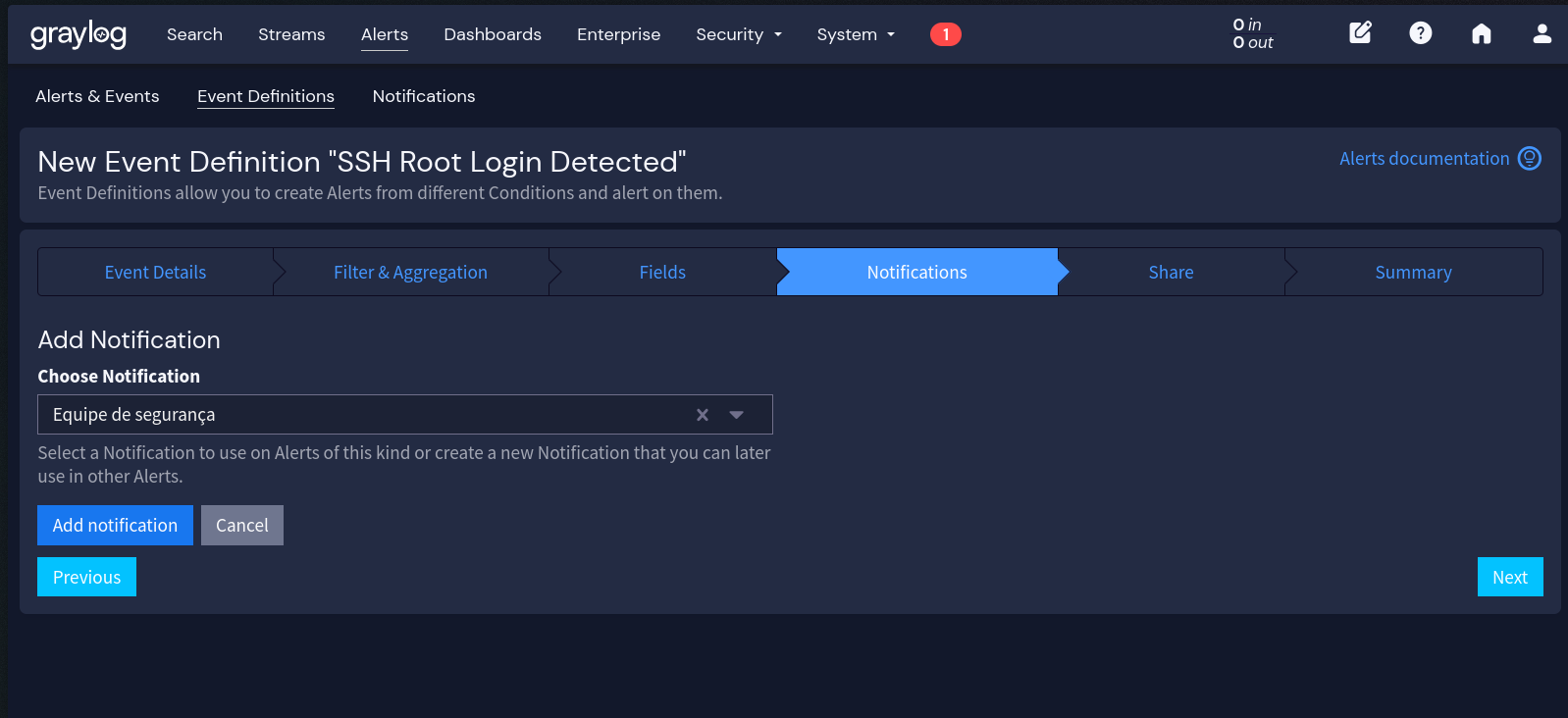
- Na aba Notifications:
- Adicione a notification “Equipe de segurança” que criamos antes
- Salve e ative a event definition
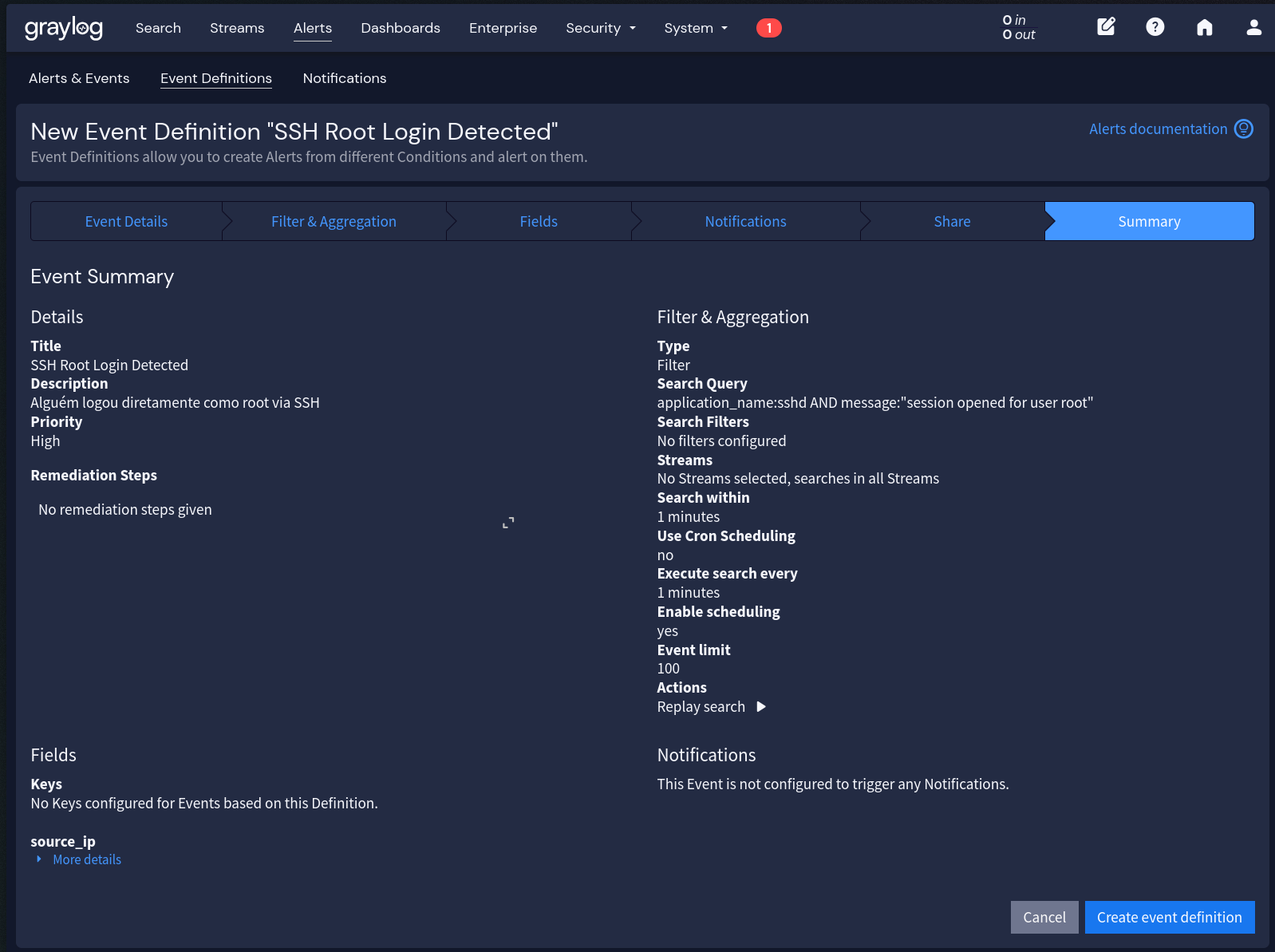
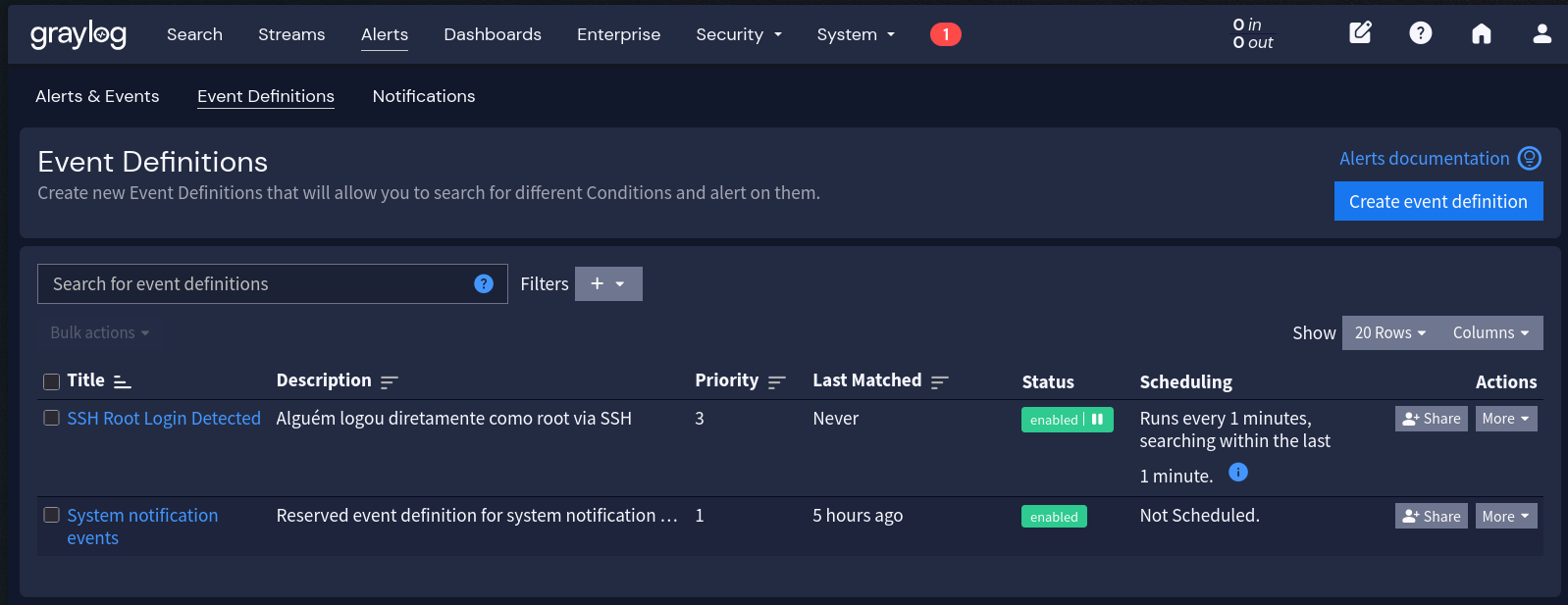
Testando o alerta:
De uma máquina que envia logs para o Graylog, faça login como root via SSH:
ssh root@servidor-monitoradoO alerta deve disparar em até 1 minuto. Verifique em Alerts > Events se o evento foi registrado e se a notificação foi enviada.
Alerta 2: Falhas de autenticação em massa
Tentativas de brute force são caracterizadas por múltiplas falhas de autenticação em curto período. Diferente do alerta anterior que busca eventos únicos, aqui estamos interessados em padrões estatísticos.
Implementação:
-
Alerts > Event Definitions > Create
-
Event Details:
- Title: Brute Force Attempt Detected
- Description: Mais de 10 falhas de autenticação SSH em 5 minutos do mesmo IP
- Priority: High
-
Condition:
- Condition Type: Filter & Aggregation
- Search Query:
application_name:sshd AND (message:"authentication failure" OR message:"Failed password") - Search within: 5 minutes
- Execute every: 1 minute
-
Aggregation:
- Clique em Add Aggregation
- Group by Fields: source (para agrupar por IP de origem)
- Aggregation Function: Count
- Threshold: > 10
-
Fields:
attacker_ip->$message.sourceattempt_count->$count
-
Notifications: Adicione a notification apropriada
Se você recebe muitos logs de servidores expostos à internet, o threshold de 10 pode ser baixo demais. Monitore os primeiros dias e ajuste conforme necessário. Alguns IPs de scan automatizado geram centenas de tentativas por hora.
Alerta 3: Comandos perigosos executados
Alguns comandos são bandeiras vermelhas quando executados, especialmente por usuários que não são administradores. Esse alerta usa os logs do tlog que configuramos no artigo anterior.
Este alerta depende do tlog funcionando corretamente conforme configurado na Parte 02. Se você pular aquela etapa ou se o tlog não estiver parseando o JSON corretamente, este alerta não vai funcionar. Volte na Parte 02 se tiver dúvidas.
Comandos que vamos monitorar:
| Comando | Risco |
|---|---|
rm -rf / (ou variações) |
Destruição de dados |
chmod 777 |
Permissões inseguras |
curl \| sh ou wget \| bash |
Execução de código remoto |
iptables -F |
Flush de firewall (iptables) |
firewall-cmd --panic-on |
Bloqueia todo tráfego (firewalld) |
systemctl stop firewalld |
Desativa firewall (firewalld) |
setenforce 0 |
Desativa SELinux |
passwd root |
Mudança de senha privilegiada |
visudo |
Modificação de sudoers |
Implementação:
-
Event Details:
- Title: Dangerous Command Executed
- Description: Comando potencialmente perigoso detectado em sessão gravada
- Priority: Medium (alguns podem ser legítimos)
-
Condition:
- Search Query:
application_name:tlog* AND ( message:"rm -rf" OR message:"chmod 777" OR message:"curl*|*sh" OR message:"wget*|*bash" OR message:"iptables -F" OR message:"iptables --flush" OR message:"firewall-cmd --panic-on" OR message:"firewall-cmd --set-default-zone=trusted" OR message:"systemctl stop firewalld" OR message:"systemctl disable firewalld" OR message:"setenforce 0" OR message:"setenforce Permissive" OR message:"passwd root" OR message:visudo ) - Search within: 1 minute
- Execute every: 1 minute
- Search Query:
-
Fields a extrair:
user->$message.TLOG_USERcommand->$message.message(trecho relevante)session_id->$message.TLOG_REC(para localizar a gravação completa)
Logs do tlog são fragmentados, cada pacote de dados digitados gera uma mensagem separada. A query pode pegar fragmentos parciais. Quando o alerta disparar, use o session_id para assistir a gravação completa e entender o contexto.
Alerta 4: Sessão tlog de usuário privilegiado
Quando alguém assume root ou outro usuário privilegiado, queremos saber imediatamente. Isso não é necessariamente um problema (pode ser manutenção legítima), mas é o tipo de evento que merece visibilidade.
Implementação:
-
Event Details:
- Title: Privileged User Session Started
- Description: Nova sessão de terminal iniciada como root ou outro usuário privilegiado
- Priority: Low (informativo)
-
Condition:
- Search Query:
application_name:tlog-rec-session AND message:"rec" AND ( TLOG_USER:root OR TLOG_USER:admin OR TLOG_USER:postgres OR TLOG_USER:mysql ) - Search within: 1 minute
- Execute every: 1 minute
- Search Query:
-
Fields:
privileged_user->$message.TLOG_USERoriginal_user->$message.TLOG_LOGIN(quem fez su/sudo)source_host->$message.source
Ajuste a lista de usuários privilegiados conforme seu ambiente. Incluir usuários de serviço como postgres e mysql ajuda a detectar acessos interativos que deveriam ser raros.
Alerta 5: Atividade fora do horário comercial
Logins às 2 da manhã de domingo geralmente não são o time de infra fazendo manutenção programada. Pode ser um atacante aproveitando horários de menor monitoramento, ou um funcionário trabalhando de forma não autorizada.
Implementação:
Esse alerta é um pouco diferente. Vamos usar um filtro de horário combinado com a query de busca.
-
Event Details:
- Title: After-Hours Activity Detected
- Description: Login ou atividade privilegiada detectada fora do horário comercial
- Priority: Medium
-
Condition:
- Search Query:
(application_name:sshd AND message:"session opened") OR (application_name:tlog-rec-session AND message:"rec") - Search within: 5 minutes
- Execute every: 5 minutes
- Search Query:
-
Pipeline para marcar horário:
O Graylog 7.x permite usar Scheduler para executar alertas apenas em determinados horários. Mas a forma mais flexível é usar um Pipeline para adicionar um campo indicando se o evento ocorreu fora do horário comercial.
Primeiro, crie a regra em System > Pipelines > Manage Rules > Create Rule:
rule "mark_after_hours" when // Horário comercial: 08:00-18:00, seg-sex (UTC-3) NOT ( hour($message.timestamp) >= 11 AND hour($message.timestamp) < 21 AND day_of_week($message.timestamp) >= 2 AND day_of_week($message.timestamp) <= 6 ) then set_field("after_hours", true); endAtenção ao fuso horário:
Alternativa mais simples: Se você usa Slack ou outro sistema de chat, crie uma notification separada que só é acionada por alertas de horário comercial. Assim você recebe o alerta sempre, mas só é notificado no chat fora do horário.
Alerta 6: Primeiro login de um usuário em um servidor
Este alerta é mais complexo que os anteriores e requer configuração adicional de Lookup Tables e Pipelines. Se você está começando, pode pular e voltar depois. Os cinco alertas anteriores já fornecem uma boa cobertura de segurança.
Um usuário que nunca acessou determinado servidor e de repente aparece lá merece atenção. Pode ser movimento lateral de um atacante usando credenciais comprometidas.
Quando você ativar esse alerta, a lookup table estará vazia (ou com dados de exemplo). O primeiro login legítimo de qualquer usuário vai disparar notificação, gerando uma “tempestade” nos primeiros dias. Duas abordagens: (1) rode a primeira semana com a notification desabilitada, deixando o sistema popular a tabela silenciosamente; ou (2) crie um script que pré-popule o CSV com base nos últimos 30 dias de logs antes de ativar.
Implementação:
Este é o alerta mais avançado. Precisamos de uma forma de rastrear “usuários conhecidos” por servidor. O Graylog oferece Lookup Tables (tabelas de consulta para cruzar dados) para isso.
Passo 1: Criar a Lookup Table
- System > Lookup Tables > Create Lookup Table
- Name: known_user_server_pairs
- Data Adapter: CSV File (para começar simples) ou HTTP JSON (para integração com CMDB)
O CSV teria formato:
key,value
user1@server1,true
user2@server1,true
admin@server2,trueA “key” é a combinação usuario@servidor, o “value” indica se é conhecido.
Passo 2: Criar Pipeline Rule
rule "check_known_user_server"
when
has_field("gl2_source_input") AND
has_field("_login_user") AND
has_field("source")
then
let user_server = concat(to_string($message._login_user), "@", to_string($message.source));
let is_known = lookup_value("known_user_server_pairs", user_server, "unknown");
if (is_known == "unknown") {
set_field("first_time_access", true);
}
endConecte o Pipeline ao Stream desejado em Streams -> [seu stream] -> Manage Pipelines.
Passo 3: Criar Event Definition
- Search Query:
first_time_access:true AND application_name:sshd AND message:"session opened" - Priority: Medium (requer investigação mas pode ser legítimo)
Abordagem alternativa: Se manter o CSV atualizado for trabalhoso, você pode usar uma abordagem baseada em baseline temporal: manter os últimos 30 dias de logins em uma lookup table e alertar quando um par usuário-servidor aparecer pela primeira vez. Isso requer mais infraestrutura (script para popular a tabela periodicamente) mas é mais realista para ambientes dinâmicos.
Streams: Organizando o fluxo de logs
Até agora criamos alertas que buscam em todos os logs. Em ambientes com volume alto, isso pode impactar performance. Streams resolvem esse problema.
O que são e por que usar
Um Stream é um filtro que separa mensagens em tempo real conforme elas chegam. Pense como pastas de email automáticas: baseado em critérios, a mensagem vai para um ou mais streams.
Benefícios:
- Performance: Alertas rodam sobre streams específicos, não sobre tudo
- Organização: Separação lógica de logs por tipo, origem ou criticidade
- Retenção diferenciada: Logs de auditoria podem ficar mais tempo que logs de debug
- Controle de acesso: Diferentes equipes podem ter acesso a diferentes streams
Streams sugeridos para auditoria
Para um ambiente focado em segurança, sugiro criar estes streams:
| Stream | Regra de Matching | Uso |
|---|---|---|
| Auditoria SSH | application_name:sshd |
Todos os alertas de SSH |
| Sessões Gravadas | application_name:tlog* |
Alertas do tlog |
| Privilege Escalation | application_name:sudo OR application_name:su |
Uso de sudo/su |
| Firewall | application_name:iptables OR application_name:nftables |
Regras de firewall |
| Security Events | facility:authpriv OR facility:auth |
Eventos de autenticação |
Criando um stream
Vamos criar o stream de Auditoria SSH como exemplo:
- Streams > Create Stream
- Preencha:
- Title: SSH Audit
- Description: Todos os logs do daemon SSH
- Index Set: Default (ou crie um específico para retenção maior)
-
Clique em Create Stream e depois em Manage Rules
-
Add Stream Rule:
- Field:
application_name - Type:
match exactly - Value:
sshd
- Field:
- Salve e clique em Start Stream
Agora, nos alertas de SSH, podemos selecionar esse stream em vez de buscar em todos os logs. A query fica mais rápida e o resultado mais preciso.
Dashboards de segurança
Alertas te avisam de problemas específicos. Dashboards te dão visão geral. Os dois se complementam.
Widgets úteis
Um dashboard de segurança eficaz combina:
Timeline de eventos de segurança
- Tipo: Histogram
- Query:
(application_name:sshd AND message:"session opened") OR first_time_access:true - Agrupa eventos ao longo do tempo para identificar padrões
Top usuários por sessões gravadas
- Tipo: Quick Values
- Field: TLOG_USER
- Mostra quem está mais ativo em sessões privilegiadas
Falhas de autenticação por origem
- Tipo: Quick Values ou World Map (se tiver GeoIP configurado)
- Query:
application_name:sshd AND message:"authentication failure" - Field: source
- Identifica origens problemáticas
Comandos perigosos detectados
- Tipo: Message List
- Query: dos alertas de comandos perigosos
- Mostra os eventos recentes para investigação rápida
Dashboard de SOC simplificado
Um layout que funciona bem:
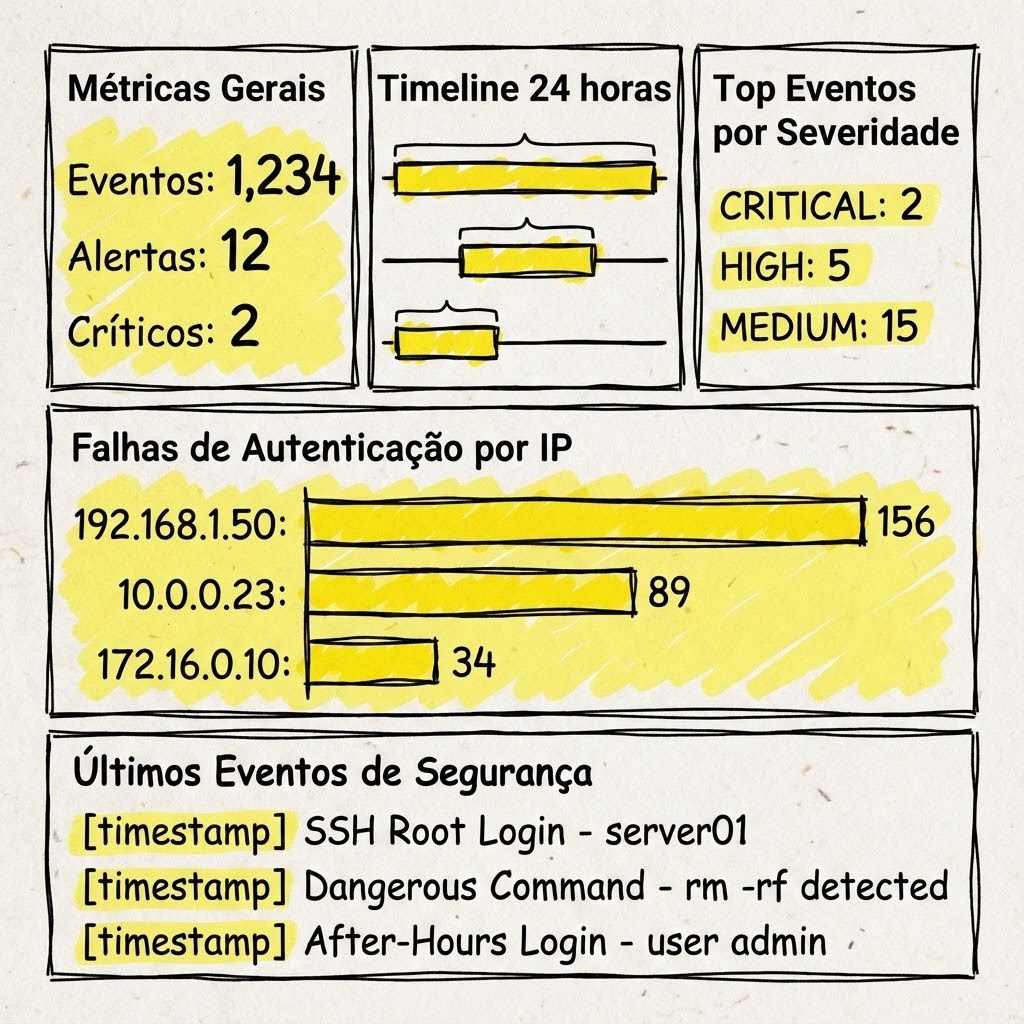
Para criar esse dashboard:
- Dashboards > Create Dashboard
- Adicione widgets usando Create > Aggregation para gráficos ou Create > Messages para listas
- Organize com drag-and-drop
- Configure refresh automático (1-5 minutos para SOC ativo)
Boas práticas
Evite fadiga de alertas
O maior inimigo de um sistema de alertas é o excesso de notificações. Quando tudo é urgente, nada é urgente.
Comece pequeno: Melhor ter 3 alertas de alta confiança que você sempre investiga do que 30 alertas que você ignora por hábito.
Use severidades corretamente:
- Critical: Incidente confirmado, requer ação imediata
- High: Muito provavelmente um problema, prioridade alta
- Medium: Requer investigação quando possível
- Low: Informativo, para awareness
Refine baseado em dados: Após uma semana, revise: quantos alertas foram falsos positivos? Ajuste thresholds e queries.
Documente as regras
Cada alerta deveria responder três perguntas:
- Por que existe? Qual cenário de ameaça ele detecta?
- O que fazer quando disparar? Passos iniciais de investigação
- Quem acionar? Se o alerta for confirmado como incidente real
Exemplo de documentação para o alerta de Brute Force:
## Alerta: Brute Force Attempt Detected
### Cenário de Ameaça
Atacante tentando adivinhar credenciais através de
múltiplas tentativas em sequência.
### Investigação Inicial
1. Verificar se o IP de origem é conhecido (VPN, parceiro, etc)
2. Checar se houve login bem-sucedido após as falhas
3. Verificar se o alvo é uma conta real ou honeypot
### Ações de Resposta
- Se IP externo desconhecido: bloquear no firewall
- Se houve sucesso: assumir conta comprometida, resetar senha
- Se conta de serviço: verificar se credencial vazou
### Escalação
- Notificar equipe de segurança se confirmado
- Abrir incidente se houve comprometimentoTeste os alertas
Não espere um incidente real para descobrir que seu alerta não funciona.
Testes de disparo: Execute as ações que deveriam disparar cada alerta. Login como root, gere falhas de autenticação, execute comandos “perigosos” em ambiente controlado.
Testes de notificação: Confirme que as mensagens chegam nos canais corretos. Email pode ir pra spam, webhook pode estar quebrado.
Exercícios periódicos: Uma vez por mês, escolha um alerta aleatório e teste toda a cadeia: disparo -> notificação -> investigação -> resposta.
Troubleshooting
Alerta não dispara
Verificar a query manualmente:
- Vá em Search
- Cole a mesma query do alerta
- Ajuste o período de tempo
- Se não retornar resultados, o problema provavelmente está na construção da query ou no recorte de tempo, não na configuração do alerta em si
Verificar o stream: Se o alerta está configurado para um stream específico, confirme que as mensagens estão chegando nesse stream. Vá em Streams e verifique o throughput.
Verificar se a Event Definition está habilitada:
- Alerts > Event Definitions
- Encontre o alerta
- Confirme que o toggle está ativado
Verificar o schedule: Alguns alertas só rodam em determinados horários. Verifique as configurações de scheduling.
Notificação não chega
Testar a notification isoladamente:
- Alerts > Notifications
- Encontre a notification
- Clique em Test Notification
- Se falhar aqui, o problema é na configuração da notification
Verificar logs do Graylog:
sudo podman logs graylog 2>&1 | grep -i "notification\|email\|smtp"Erros de conexão SMTP, timeout de webhook, etc. aparecem aqui.
Verificar rede:
- Email: porta 587/465 bloqueada?
- Webhook: URL acessível do container? Proxy necessário?
Muitos falsos positivos
Refinar a query:
# Muito amplo
message:"authentication failure"
# Mais específico
application_name:sshd AND message:"authentication failure" AND NOT source:10.0.0.0/8Adicionar exceções: Use NOT para excluir IPs conhecidos, usuários de serviço, etc.
Ajustar thresholds: Se agregação está disparando muito, aumente o threshold ou a janela de tempo.
Criar whitelist: Para alertas como “primeiro acesso”, mantenha uma lookup table de acessos conhecidos e legítimos.
Conclusão
Agora o Graylog trabalha pra você. Em vez de ficar caçando problemas nos logs, você é avisado quando algo merece atenção.
Os seis alertas que criamos cobrem cenários comuns:
- Login direto como root (violação de política)
- Brute force (ataque em progresso)
- Comandos perigosos (atividade suspeita)
- Sessões privilegiadas (awareness)
- Atividade fora de horário (anomalia temporal)
- Primeiro acesso (movimento lateral potencial)
Mas não se esqueça: alertas são ponto de partida, não linha de chegada. O valor está no que você faz depois que o alerta dispara.
No próximo artigo, vamos explorar correlação de eventos e detecção de padrões mais complexos, quando um alerta sozinho não conta a história completa, mas a combinação de vários eventos revela o que realmente está acontecendo.
Recursos adicionais
Arquivos de apoio
Os arquivos de configuração e o content pack com os alertas deste artigo estão disponíveis no repositório:
03-alertas/
\_ compose-email.yaml # Extensão do compose.yaml com configuração de email
\_ .env.example # Variáveis de ambiente incluindo SMTP
\_ alertas-seguranca.json # Content Pack com todos os alertas do artigo
\_ pipeline-after-hours.txt # Pipeline rules para marcação fora de horário
\_ slack-payload-completo.json # Payload completo para Slack com blocos
\_ test-alerts.sh # Script para testar os alertasPara importar o content pack:
- System > Content Packs > Upload
- Selecione o arquivo
alertas-seguranca.json - Revise os componentes e clique em Install



Comentários
Comentários fechados para visitantes. Entre ou registre-se para comentar.