
O “Hype” vs. O Boleto
O mundo da tecnologia vive de ciclos de hype. Há 10 anos, se você não estivesse quebrando seu sistema em microsserviços, você era um dinossauro. Hoje, se você não está “serverless-first”, você está atrasado.
O problema é que a arquitetura de software não é sobre seguir moda, é sobre pagar boletos (seja na dor de cabeça ou no cartão de crédito).
Neste artigo, vamos descer do pedestal da arquitetura de software e olhar para as três principais abordagens atuais: Monolito, Microsserviços e Função como Serviço (FaaS), com um olhar pragmático. Vamos entender quando cada um brilha e, mais importante, quando cada um vai fazer sua vida um inferno.
1. O Monolito: O “vingador” injustiçado
O monolito virou xingamento em muitas rodinhas de TI. Mas vamos ser honestos: ele é a melhor escolha para 90% dos projetos que estão nascendo.
O que é na prática:
É aquele sistema onde tudo (interface do usuário, lógica de negócios, acesso ao banco de dados) vive em um único repositório de código e é implantado como uma única unidade (um .jar, um binário Go, uma aplicação Rails).
É como uma casa de um cômodo só, em que a cozinha é integrada à sala e ao quarto.
O lado bom (O “mel”):
- Simplicidade operacional: É só um binário para fazer deploy. É só um lugar para olhar os logs.
- Performance local: Nenhuma latência de rede entre chamar a função
CalcularFretee a funçãoBuscarUsuario. É tudo memória local. - Debug: Colocar um breakpoint e seguir o fluxo é trivial.
O lado ruim (O “fel”):
- O medo do deploy: Se você muda uma linha no módulo de “Pagamentos”, você precisa redeployar o sistema inteiro. Se der pau, cai tudo, até o “Cadastro de Usuário”.
- Escala tudo-ou-nada: Se o módulo de “Processamento de Imagens” está gargalando a CPU, você precisa escalar a máquina inteira, desperdiçando memória no resto do sistema que estava ocioso.

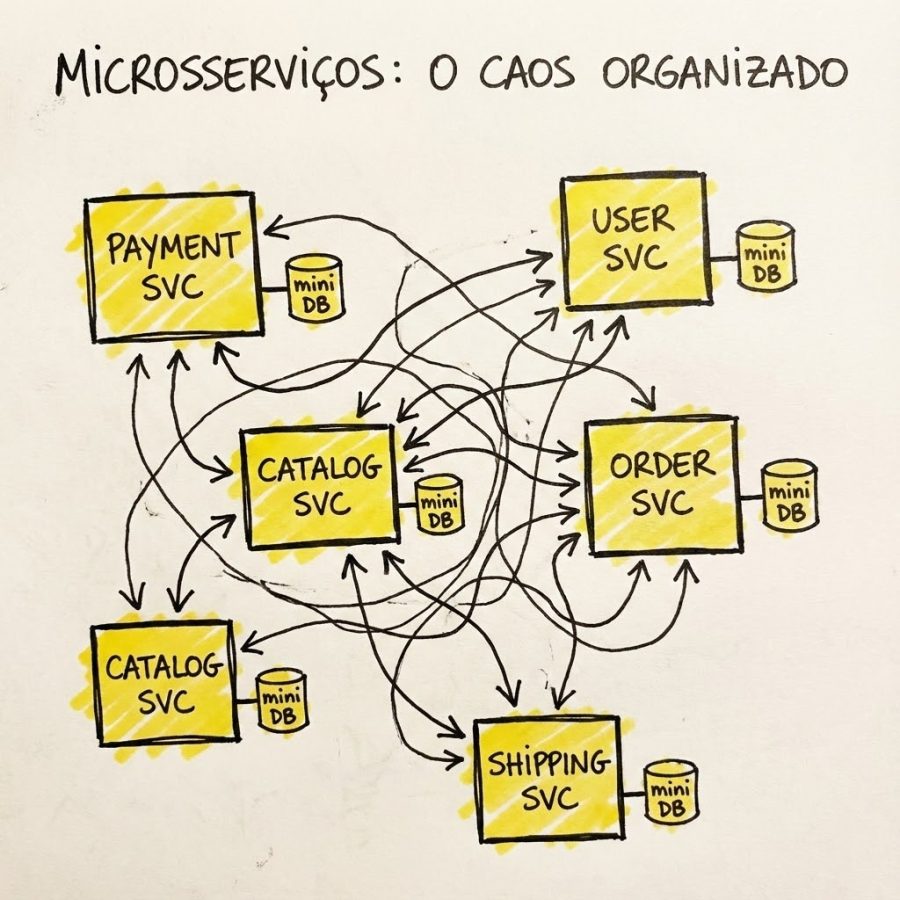
2. Microsserviços: O caos organizado
Microsserviços surgem quando o monolito fica tão grande que ninguém mais tem coragem de mexer nele. A ideia é dividir para conquistar.
Como funciona o caos: Você pega aquele monolito e quebra em serviços pequenos e independentes, divididos por contexto de negócio (ex: Serviço de Pagamento, Serviço de Catálogo, Serviço de Usuário). Cada um tem seu próprio banco de dados e eles conversam entre si via rede (HTTP/gRPC).
Agora você tem vários prédios separados. Cada prédio tem seu síndico e suas regras. Se um prédio pega fogo, os outros continuam funcionando. Mas para ir da portaria A para a portaria B, você precisa pegar o carro e encarar o trânsito.
O lado bom:
- Escala independente: O serviço de “Catálogo” recebe muita leitura? Escala só ele.
- Times independentes: O time de Java cuida do Pagamento, o time de Node cuida do Catálogo. Ninguém pisa no pé de ninguém.
- Resiliência: Se o serviço de “Recomendações” cair, o usuário ainda consegue comprar o produto.
O lado ruim (a dor que ninguém te conta):
- A rede não é confiável: O que antes era uma chamada de função local, agora é uma chamada de rede. A rede vai falhar. Você precisa de retries, circuit breakers e timeouts.
- Complexidade operacional: Agora você não monitora 1 aplicação, você monitora 50. Você precisa de orquestração (Kubernetes), tracing distribuído (Jaeger/Grafana Tempo) e service mesh. A infraestrutura vira um produto em si.
História de guerra: O sifão de tempo
E se isso parece teórico, aqui vai o que aconteceu quando a gente antecipou essa complexidade cedo demais: num projeto antigo, cometemos o pecado capital de construir microsserviços desde o dia 1. Na teoria, parecia “arquitetura moderna”. Na prática, virou um sifão de tempo gigantesco.
O contexto era o pior possível: time pequeno e um produto que ainda nem tinha se provado. O primeiro sinal de alerta veio nos bugs. O que no monolito seria um git commit simples e um deploy, virou uma via sacra: a mesma correção precisava ser aplicada em mais de quinze repositórios diferentes. Cada um com seu pipeline, sua versão, seu risco de quebrar.
Mas o verdadeiro pesadelo foi a rede. De repente, tudo virou “culpa da rede”.
Não era “a internet caiu”. Era aquele erro fantasma: timeout intermitente, request sumindo, comportamento que só acontecia às 2 da manhã. A gente passava horas caçando logs, olhando trace incompleto, culpando DNS, NAT, Load Balancer… pra no final descobrir que o código estava certo o tempo todo. O problema era a complexidade que nós criamos.
E o golpe de misericórdia? Para coroar o desastre, a equipe de infraestrutura nos entregou um único banco de dados gigante para todos os microsserviços conectarem.
Criamos o pior Frankenstein da engenharia de software: o Monolito Distribuído. Tínhamos toda a latência e complexidade de rede dos microsserviços, mas se o banco travasse uma tabela (e travou), os 15 serviços morriam abraçados instantaneamente. Compramos o custo da Netflix e a fragilidade de um castelo de cartas.
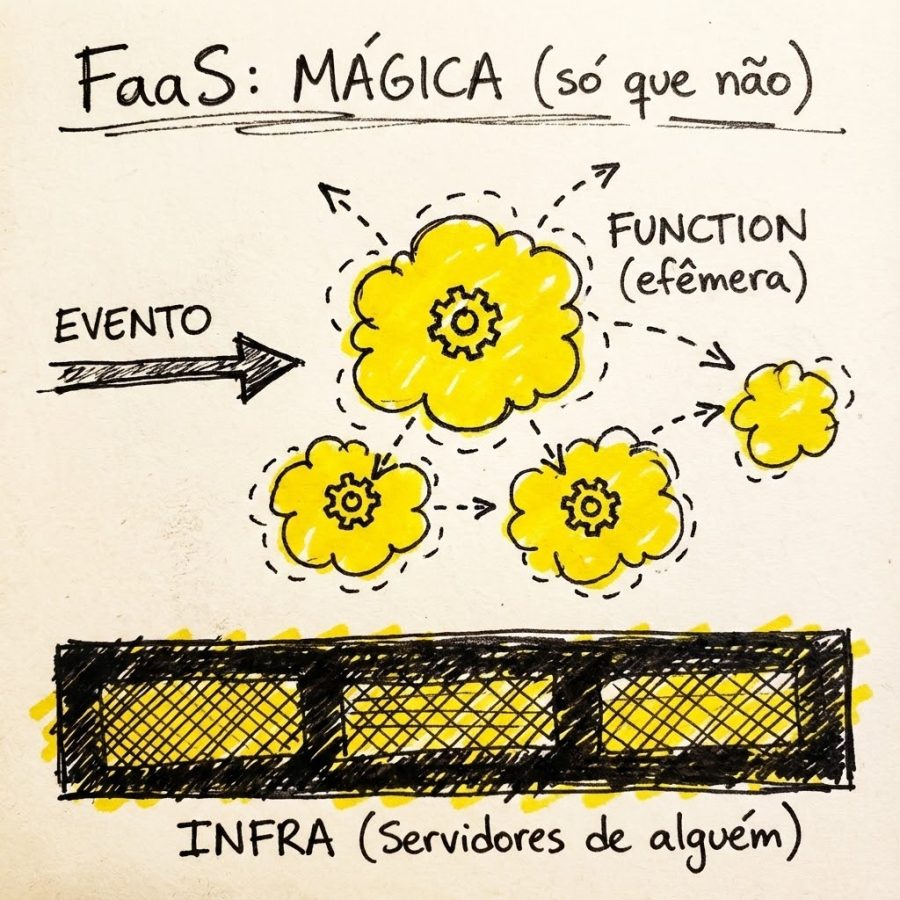
3. FaaS (serverless): A abstração final… e suas mentiras
Chegamos ao FaaS (AWS Lambda, Google Cloud Functions, Azure Functions). A promessa é o nirvana: esqueça servidores, foque apenas no código.
A mecânica da coisa: Você escreve uma função (ex: “Redimensionar imagem quando um upload acontece no S3”). Você sobe o código e a nuvem se vira. Se chegar uma requisição, ela atende. Se chegarem mil, ela escala. Você não configura servidor, só paga a execução. Se tiver 1 evento, ela roda uma vez. Se tiver 1 milhão de eventos simultâneos, ela (teoricamente) roda 1 milhão de vezes.
Pense no Monolito como seu carro próprio: você lava, abastece, troca o óleo e paga IPVA (manutenção do servidor) mesmo que ele fique parado na garagem o mês todo. O FaaS é o Uber. Você não tem carro, não paga seguro e nem sabe trocar pneu. Você só abre o app, o motorista aparece, te leva do ponto A ao ponto B (executa o código) e vai embora. A corrida foi rápida? Você paga centavos. Ficou o dia todo em casa? Gasta zero.
A sacada: “Serverless” é mentira. Sempre tem servidor. A diferença é que você terceirizou a dor de cabeça.
- O segredo: Nos bastidores, provedores como a AWS usam tecnologias de virtualização ultra-leve. É aqui que entra o Firecracker (que já mencionamos aqui no blog). Quando sua função precisa rodar, eles sobem uma microVM em milissegundos, executam seu código e matam a microVM. É a efemeridade levada ao extremo.
O lado bom:
- Custo zero se ocioso: Se ninguém acessar seu site de madrugada, você paga zero reais.
- Escala “infinita”: Ótimo para picos de tráfego imprevisíveis.
O lado ruim:
- Cold starts: Se sua função está “fria” (a microVM não está pronta), a primeira requisição pode levar segundos para responder. Terrível para APIs que precisam de baixa latência.
- Vendor lock-in: Sua lógica fica extremamente acoplada aos eventos específicos daquela nuvem (DynamoDB streams, S3 events). Mudar de nuvem é um parto.
- Ambiente de desenvolvimento: Testar uma arquitetura complexa de FaaS na sua máquina local é um pesadelo.
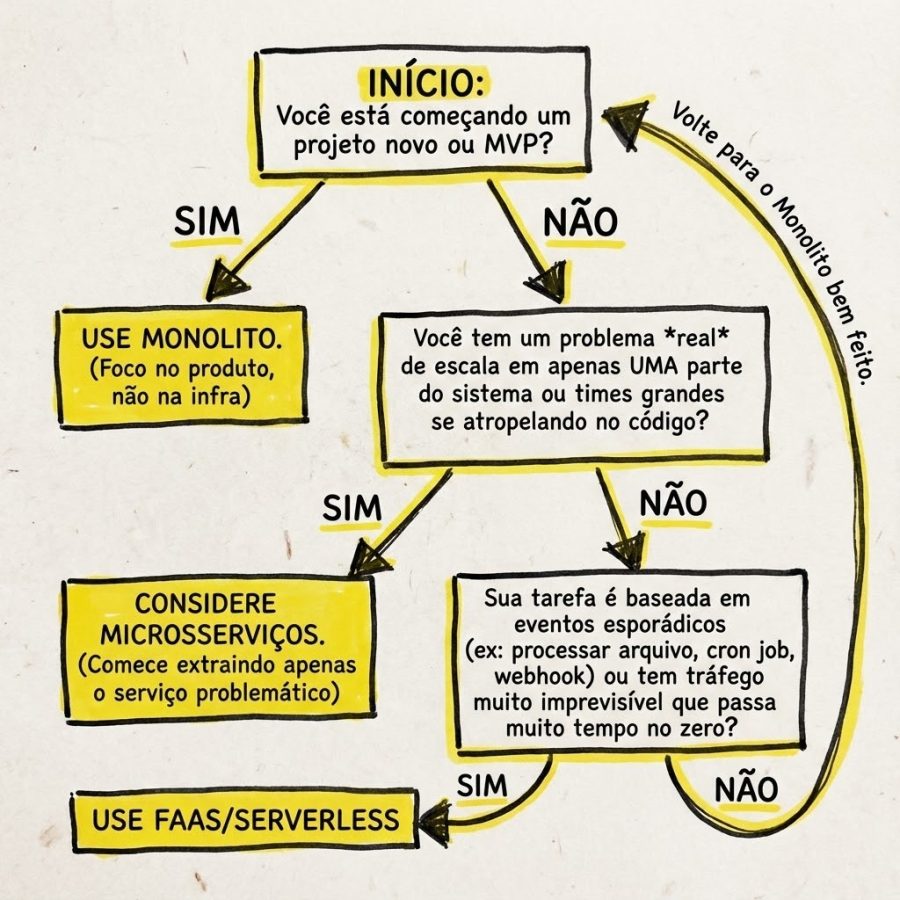
Como decidir o que usar
Para facilitar, montei esse fluxo. A regra de ouro é: se você tiver dúvida, a resposta provavelmente é não use microsserviços.
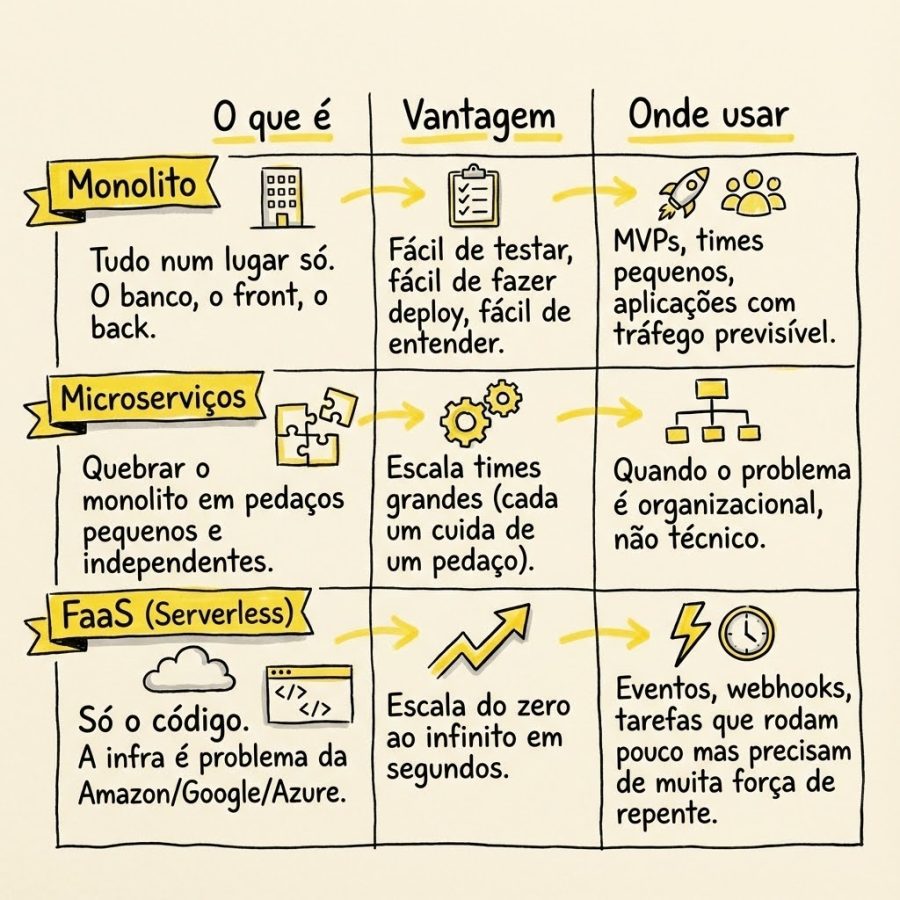
Não existe bala de prata, existe a ferramenta certa para o tamanho do seu problema.
Conclusão
Arquitetura é sobre escolhas e consequências. Começar com microsserviços porque a Netflix usa é como comprar um caminhão Scania para ir à padaria comprar pão. Funciona? Funciona. Mas você vai gastar uma fortuna de diesel e não vai conseguir estacionar.
Na dúvida, mantenha a simplicidade. É mais fácil transformar um monolito bem feito em microsserviços no futuro do que tentar juntar os cacos de um sistema distribuído caótico que foi criado cedo demais.

Comentários
Comentários fechados para visitantes. Entre ou registre-se para comentar.