Por que engenheiros sênior pensam primeiro em failure modes, e como você pode fazer o mesmo
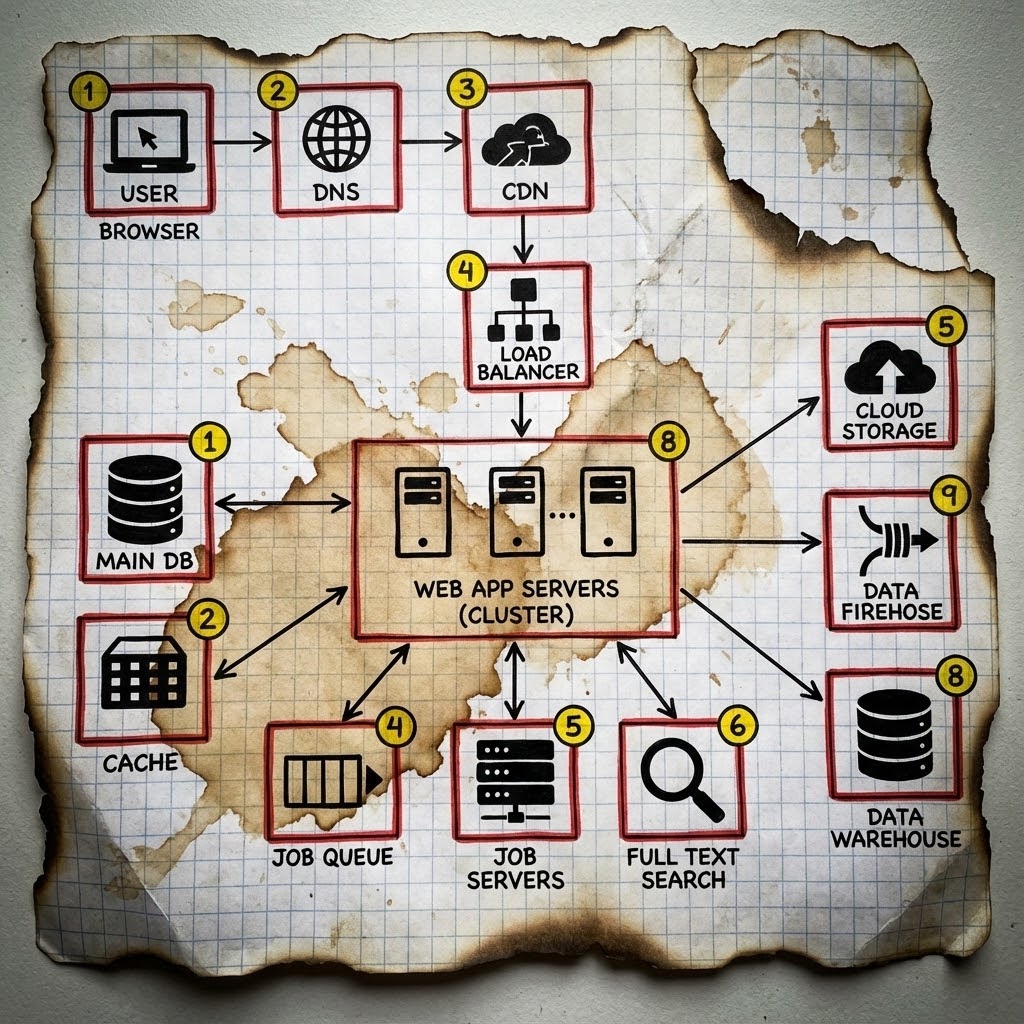
O diagrama bonito que não salva ninguém
Toda reunião de arquitetura começa igual. Alguém abre o Excalidraw, desenha umas caixinhas, conecta com setas, e pronto: nasceu mais um sistema “escalável e resiliente”.
Bonito. Limpo. Profissional.
E completamente inútil às 3h da manhã de uma sexta-feira.
Em mais de 20 anos trabalhando com infraestrutura, incluindo quase uma década na IBM lidando com sistemas que não podiam cair, nunca vi um sistema falhar pelo que estava no diagrama. Sempre pelo que ficou de fora.
A falha que ninguém desenhou (e o Retry Storm que derrubou tudo)
Deixa eu te contar uma história real.
Sistema em produção. Três backends atrás de um HAProxy. Health check configurado “certinho”: TCP na porta 8080 a cada 5 segundos.
backend app_servers
balance roundrobin
option httpchk GET /
server app1 10.0.1.10:8080 check
server app2 10.0.1.11:8080 check
server app3 10.0.1.12:8080 checkSó que o health check estava errado. Ele verificava se a porta respondia, não se a aplicação funcionava. A diferença?
Um deploy quebrado subiu em dois dos três servidores. A aplicação inicializou, abriu a porta 8080, mas travava no primeiro request real, um deadlock no pool de conexões com o banco.
O HAProxy via: “Porta aberta? Backend saudável!”
O usuário via: loading… loading… timeout.
Resultado: 33% dos requests funcionavam. Os outros 66%? Timeout de 30 segundos. E como o cliente tinha retry automático configurado, cada request falhado virava três.
Retry Storm: O amplificador de desastres
Esse fenômeno tem nome: Retry Storm. Quando múltiplos clientes detectam falhas e fazem retry simultaneamente, a carga no sistema pode aumentar exponencialmente.
Request original: 1 req
Primeiro retry: 2 reqs (original + retry)
Segundo retry: 3 reqs
Com 1000 usuários: 3000 reqs em vez de 1000
Sistema já degradado + 3x a carga = colapso totalA mitigação correta: Exponential backoff com jitter.
def retry_with_backoff(max_retries: 5)
attempt = 0
begin
yield
rescue StandardError => e
attempt += 1
raise e if attempt >= max_retries
# Exponential backoff: 1s, 2s, 4s, 8s...
base_delay = 2**attempt
# Jitter: adiciona variação aleatória de 0-50%
# Isso evita que todos os clientes façam retry no mesmo instante
jitter = rand * 0.5 * base_delay
sleep(base_delay + jitter)
retry
end
end
# Uso:
retry_with_backoff(max_retries: 3) do
api_client.fetch_user(user_id)
endSem o jitter, todos os clientes que falharam no segundo 0 vão fazer retry no segundo 1. Com jitter, eles se espalham entre os segundos 1.0 e 1.5, distribuindo a carga.
O problema é filosófico, não técnico
Esse incidente não aconteceu por incompetência. Aconteceu por filosofia de design.
Arquitetos desenham como o sistema funciona.
Engenheiros sênior desenham como o sistema falha.
A diferença entre um sistema que “deveria funcionar” e um sistema que “funciona em produção” está nas perguntas que você faz antes de escrever a primeira linha de código.
As 5 perguntas que separam júnior de sênior
Antes de aprovar qualquer design, meu ou de outra pessoa, eu faço essas cinco perguntas. Se alguém não souber responder, encontramos o próximo incidente antes dele acontecer.
1. “E se esse componente morrer agora?”
Não “se falhar graciosamente”. Se morrer. Crash brabo. Sem aviso. Sem log. Sem cleanup.
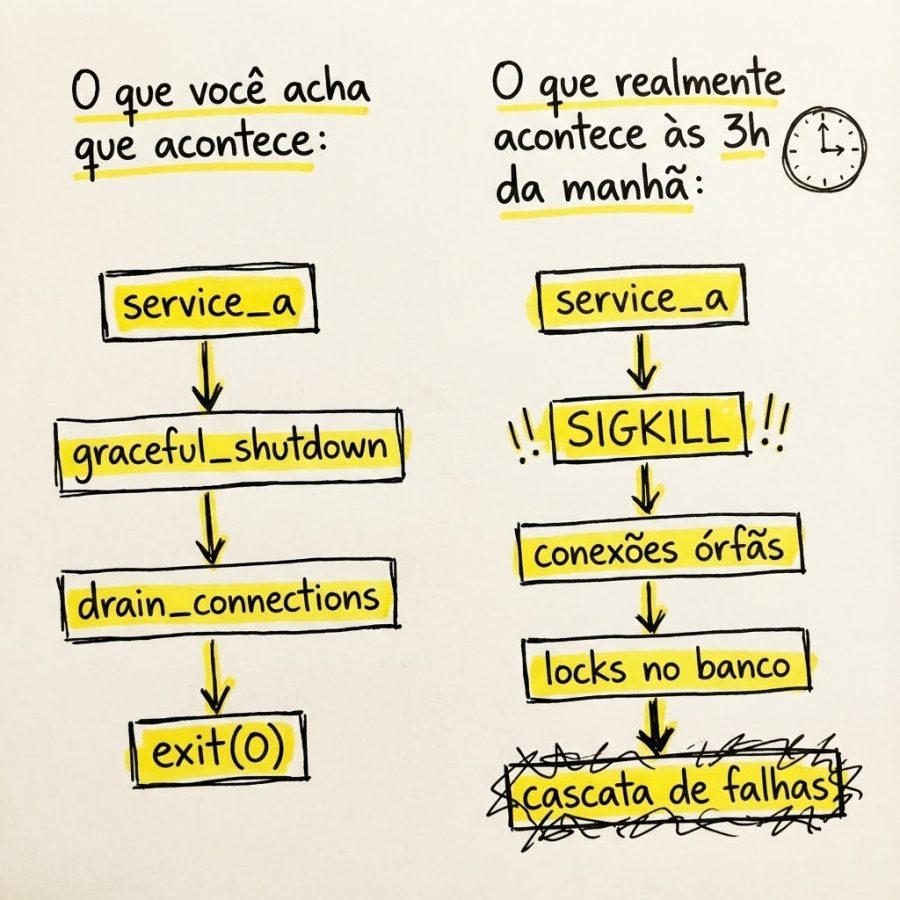
Teste prático: Mate o processo com kill -9 em staging. Não kill -15. Não graceful shutdown. O -9 que a realidade usa.
2. “E se a latência triplicar em vez de dar erro?”
Timeout lento é pior que falha rápida. Muito pior.
Quando um serviço retorna erro, seu circuit breaker abre, o retry desiste, a vida continua. Quando um serviço fica lento, as conexões ficam presas esperando, o pool esgota, as filas enchem, e de repente você tem um efeito dominó.
# Isso aqui é uma bomba-relógio:
response = Net::HTTP.get(uri)
# Isso aqui é profissionalismo:
http = Net::HTTP.new(uri.host, uri.port)
http.open_timeout = 2 # Timeout para abrir conexão
http.read_timeout = 5 # Timeout para receber resposta
begin
response = http.request(Net::HTTP::Get.new(uri))
rescue Net::OpenTimeout, Net::ReadTimeout => e
# Falha rápida, libera recursos, segue a vida
Rails.logger.error("Request timeout: #{e.message}")
raise ServiceUnavailableError
endPergunta de follow-up: Seu circuit breaker detecta lentidão ou só erros? Se só detecta erros, você tem um problema.
3. “E se o banco aceitar escritas mas rejeitar leituras?”
Parece impossível? Já vi isso acontecer.
PostgreSQL com disco cheio para WAL (Write-Ahead Log) mas ainda com espaço nas tablespaces. Escritas funcionavam. Leituras de tabelas grandes? Timeout.
MySQL com replica lag tão alto que leituras no replica retornavam dados de 30 minutos atrás. O sistema “funcionava”, só que o usuário via os status de meia hora antes.
-- Health check ingênuo:
SELECT 1;
-- Health check que pega problema real (e não sobrecarrega o banco):
SELECT updated_at FROM critical_table ORDER BY updated_at DESC LIMIT 1;
-- A aplicação verifica se esse timestamp é recente (< 5 min)4. “E se der sucesso mas com dado errado?”
A falha silenciosa (Silent Failure). O request retorna 200 OK. O JSON está bem formado. Só que o conteúdo está errado.
// Request: GET /api/user/123/balance
// Response: 200 OK
{
"user_id": 123,
"balance": 0.00,
"currency": "BRL"
}
// Pergunta: o saldo é zero ou o serviço de saldo está fora e retornou default?Estratégias de mitigação:
- Campos obrigatórios que indicam “dado real” vs “dado default“
- Timestamps de quando o dado foi gerado
- Checksums ou hashes de integridade
- Monitoramento de anomalias (saldo zero para todos usuários = alerta)
5. “E se tudo isso acontecer junto?”
Porque em produção, vai acontecer. Numa sexta. Antes do feriado. Durante o deploy.
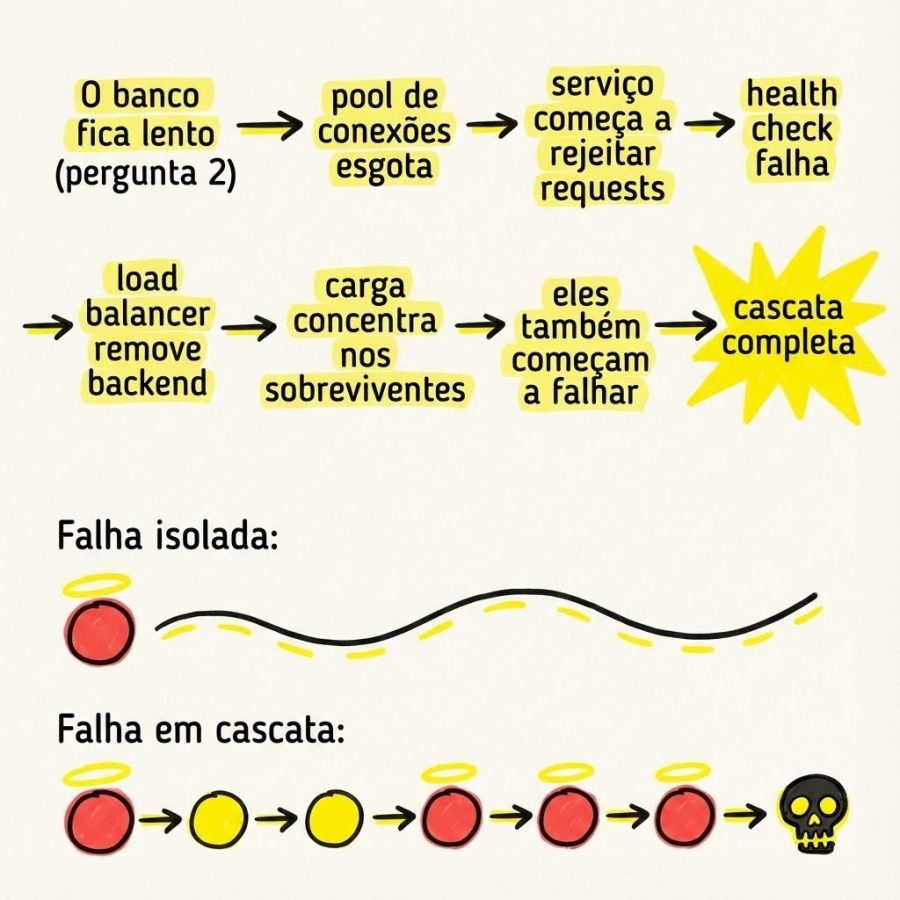
Chaos Engineering: Escolhendo quando falhar
A Netflix popularizou o conceito com o Chaos Monkey em 2011, uma ferramenta que matava instâncias aleatoriamente em produção. A ideia era simples: se você sabe que coisas vão falhar, melhor descobrir as fraquezas durante horário comercial do que às 3h da manhã.
Você escolhe se descobre a falha numa terça às 14h com todo mundo acordado, ou sábado às 4h quando só tem um plantonista junior.
Abordagem prática: Comece manual
Antes de adotar ferramentas complexas, você pode (e deve) começar com chaos engineering manual. Isso te dá controle total e entendimento profundo do que está testando.
1. Mate processos sem aviso
# Em staging, encontre o PID do seu serviço
pgrep -f "puma"
# Mate sem piedade (simula crash real)
kill -9 $(pgrep -f "puma" | head -1)
# Observe: quanto tempo até o load balancer detectar?
# Quanto tempo até o orchestrator subir nova instância?2. Simule problemas de rede com tc (traffic control)
O tc faz parte do pacote iproute2, que já vem instalado na maioria das distros. Se precisar instalar:
# Ubuntu/Debian
sudo apt install iproute2
# Fedora
sudo dnf install iprouteUso:
# Adiciona 500ms de latência em toda comunicação
tc qdisc add dev eth0 root netem delay 500ms
# Adiciona latência variável (mais realista)
tc qdisc add dev eth0 root netem delay 200ms 100ms
# Simula 10% de perda de pacotes
tc qdisc add dev eth0 root netem loss 10%
# Remove as regras quando terminar
tc qdisc del dev eth0 root3. Simule disco cheio
# Cria arquivo gigante até encher o disco
dd if=/dev/zero of=/var/lib/postgresql/fakefile bs=1M count=10000
# Observa o que acontece com o banco
# Remove depois
rm /var/lib/postgresql/fakefile4. Simule CPU sob pressão
Primeiro, instale o stress-ng:
# Ubuntu/Debian
sudo apt install stress-ng
# Fedora
sudo dnf install stress-ngUso:
# Consome 4 cores por 60 segundos
stress-ng --cpu 4 --timeout 60s
# Ou com limite específico de carga
stress-ng --cpu 2 --cpu-load 80 --timeout 30sFerramentas para escalar
Quando você entender os failure modes manualmente, pode escalar com ferramentas:
| Ferramenta | Ambiente | Manutenção | Destaques |
|---|---|---|---|
| Chaos Mesh | Kubernetes | Ativa (CNCF) | Interface web, workflows declarativos |
| LitmusChaos | Kubernetes | Ativa (CNCF) | Hub de experimentos prontos, GitOps |
| Toxiproxy | Qualquer | Ativa | Simula falhas de rede, fácil de integrar |
| Pumba | Docker | Ativa | Chaos para containers, kill/pause/stress |
CNCF (Cloud Native Computing Foundation) é a fundação que mantém projetos como Kubernetes e Prometheus. Projetos sob a CNCF têm governança aberta e suporte ativo da comunidade.
O Toxiproxy é especialmente útil para simular problemas de rede entre serviços.
Instalação:
# Ubuntu/Debian
wget -qO - https://github.com/Shopify/toxiproxy/releases/download/v2.9.0/toxiproxy_2.9.0_linux_amd64.deb
sudo dpkg -i toxiproxy_2.9.0_linux_amd64.deb
# Fedora
sudo dnf install toxiproxyUso:
# Cria proxy para o PostgreSQL
toxiproxy-cli create postgres_proxy -l localhost:15432 -u localhost:5432
# Simula latência fixa de 2 segundos
toxiproxy-cli toxic add -t latency -a latency=2000 postgres_proxy
# Simula latência variável (mais realista!)
# Latência entre 100ms e 5000ms - isso quebra timeouts mal configurados
toxiproxy-cli toxic add -t latency -a latency=2500 -a jitter=2500 postgres_proxy
# Simula conexões sendo cortadas
toxiproxy-cli toxic add -t reset_peer -a timeout=1000 postgres_proxyPrincípios fundamentais
1. Sempre tenha hipótese antes de experimento
Não é “vamos ver o que acontece”. É “acreditamos que se X falhar, Y vai assumir em menos de 30 segundos”.
Antes de rodar qualquer experimento de chaos, documente:
- name: identificador único do experimento
- hypothesis: o que você acredita que vai acontecer (testável e mensurável)
- method: como você vai provocar a falha
- expected_result: critério de sucesso/falha objetivo
- rollback: como voltar ao estado anterior se der ruim
Exemplo documentado:
experiment:
name: "database-failover"
hypothesis: "Se primary DB cair, replica assume em < 30s"
method: "kill primary database pod"
expected_result: "zero requests com erro 5xx durante failover"
rollback: "restore primary from snapshot"Se a hipótese falhar (o failover demorou 2 minutos, por exemplo), você descobriu uma fraqueza antes que ela te acordasse de madrugada.
2. Comece pequeno, aumente gradualmente
A evolução natural de um programa de chaos engineering:
- Semana 1: Mata 1 pod em staging
- Semana 2: Mata 2 pods em staging
- Semana 3: Simula falha de AZ em staging
- Mês 2: Mata 1 pod em produção (fora do horário de pico)
- Mês 3: Experimentos regulares em produção
Não pule etapas. Cada fase te ensina algo que você vai precisar na próxima.
3. Tenha sempre um botão de rollback
Antes de qualquer experimento, saiba exatamente como reverter. Se não sabe, não execute.
O Framework de Failure Mode Analysis
Antes de qualquer review de arquitetura, eu preencho essa tabela para cada componente crítico:
| Componente | Modo de falha | Impacto | Detecção | Mitigação | Graceful degradation |
|---|---|---|---|---|---|
| Load Balancer | Crash total | Crítico | Health check externo | LB redundante | N/A (crítico) |
| Load Balancer | Config errada | Alto | Canary deploy | Rollback automático | Rota para versão anterior |
| API Gateway | Memory leak | Médio | Métricas de memória | Auto-restart | Rate limiting preventivo |
| Database | Disco cheio | Crítico | Alertas de capacidade | Auto-scaling storage | Modo read-only |
| Database | Replica lag | Médio | Monitoramento de lag | Health check no replica | Reads no primary |
| Cache | Eviction massiva | Alto | Hit rate monitoring | Cache warming | Servir stale content |
| Message Queue | Backlog crescente | Médio | Queue depth alerts | Auto-scaling consumers | Drop mensagens não-críticas |
A coluna “Graceful degradation” é crucial. Não basta ter mitigação, você precisa saber como o sistema se comporta enquanto você mitiga.
Por exemplo, se o cache falha:
- Mitigação: Cache warming, restart dos nodes
- Graceful degradation: Servir conteúdo stale (antigo) por 5 minutos, desativar recomendações personalizadas, ativar rate limiting para proteger o banco
Perguntas para cada linha:
- Como detectamos essa falha automaticamente?
- Qual o tempo entre falha e detecção (MTTD)?
- Qual o tempo entre detecção e recuperação (MTTR)?
- O que acontece com os requests durante a recuperação?
- Precisamos de intervenção humana ou é automático?
- O que podemos desligar para manter o core funcionando?
Health checks que realmente funcionam
A maioria dos health checks que vejo em produção são variações de:
# Health check inútil
get '/health' do
status 200
'OK'
endIsso só prova que o processo está rodando. Não prova que funciona.
Níveis de health check
/health/live -> Processo está rodando? (para Kubernetes liveness)
/health/ready -> Pronto para receber tráfego? (para Kubernetes readiness)
/health/full -> Todas as dependências funcionando? (para debugging)ALERTA CRÍTICO: O Anti-Padrão do Liveness Probe
Nunca coloque verificação de dependências externas no liveness probe.
Se seu /health/live checa o banco de dados e o banco fica lento, o que acontece?
- Liveness falha
- Kubernetes mata o pod
- Kubernetes sobe novo pod
- Novo pod tenta conectar no banco (já sobrecarregado)
- Liveness falha de novo
- Restart loop infinito
Enquanto isso, a carga de reconnect dos pods reiniciando piora a situação do banco.
Regra de ouro:
/health/livedeve ser simples: retorna 200 se o binário está rodando. Só isso./health/readyé quem checa dependências para tirar o tráfego, sem matar o processo.
Health check liveness (simples de propósito)
# Liveness: só verifica se o processo responde
get '/health/live' do
status 200
content_type :json
{ status: 'alive', timestamp: Time.now.utc.iso8601 }.to_json
endHealth check readiness (completo)
get '/health/ready' do
checks = {}
overall_status = :healthy
# Verifica conexão com banco
db_start = Process.clock_gettime(Process::CLOCK_MONOTONIC)
begin
ActiveRecord::Base.connection.execute('SELECT 1')
checks[:database] = {
status: 'healthy',
duration_ms: ((Process.clock_gettime(Process::CLOCK_MONOTONIC) - db_start) * 1000).round(2)
}
rescue StandardError => e
checks[:database] = {
status: 'unhealthy',
duration_ms: ((Process.clock_gettime(Process::CLOCK_MONOTONIC) - db_start) * 1000).round(2),
message: e.message
}
overall_status = :unhealthy
end
# Verifica cache (Redis)
cache_start = Process.clock_gettime(Process::CLOCK_MONOTONIC)
begin
Redis.current.ping
checks[:cache] = {
status: 'healthy',
duration_ms: ((Process.clock_gettime(Process::CLOCK_MONOTONIC) - cache_start) * 1000).round(2)
}
rescue StandardError => e
checks[:cache] = {
status: 'unhealthy',
duration_ms: ((Process.clock_gettime(Process::CLOCK_MONOTONIC) - cache_start) * 1000).round(2),
message: e.message
}
overall_status = :unhealthy
end
# Unhealthy = tira do pool de tráfego, mas NÃO mata o pod
status overall_status == :healthy ? 200 : 503
content_type :json
{
status: overall_status,
timestamp: Time.now.utc.iso8601,
checks: checks
}.to_json
endImplementação em rails (controller)
# app/controllers/health_controller.rb
class HealthController < ApplicationController
# Pula autenticação para health checks
skip_before_action :authenticate_user!
# GET /health/live
def live
render json: { status: 'alive' }, status: :ok
end
# GET /health/ready
def ready
checks = {
database: check_database,
redis: check_redis,
sidekiq: check_sidekiq
}
all_healthy = checks.values.all? { |c| c[:status] == 'healthy' }
render json: {
status: all_healthy ? 'healthy' : 'unhealthy',
timestamp: Time.current.utc.iso8601,
checks: checks
}, status: all_healthy ? :ok : :service_unavailable
end
private
def check_database
start = Process.clock_gettime(Process::CLOCK_MONOTONIC)
ActiveRecord::Base.connection.execute('SELECT 1')
{ status: 'healthy', duration_ms: elapsed_ms(start) }
rescue StandardError => e
{ status: 'unhealthy', duration_ms: elapsed_ms(start), error: e.message }
end
def check_redis
start = Process.clock_gettime(Process::CLOCK_MONOTONIC)
Redis.current.ping
{ status: 'healthy', duration_ms: elapsed_ms(start) }
rescue StandardError => e
{ status: 'unhealthy', duration_ms: elapsed_ms(start), error: e.message }
end
def check_sidekiq
start = Process.clock_gettime(Process::CLOCK_MONOTONIC)
Sidekiq.redis(&:ping)
{ status: 'healthy', duration_ms: elapsed_ms(start) }
rescue StandardError => e
{ status: 'unhealthy', duration_ms: elapsed_ms(start), error: e.message }
end
def elapsed_ms(start)
((Process.clock_gettime(Process::CLOCK_MONOTONIC) - start) * 1000).round(2)
end
endPostmortem: A falha como professor
Todo incidente é uma aula gratuita. Mas só se você documentar direito.
Template de postmortem
## Incidente: [Nome descritivo]
**Data:** YYYY-MM-DD
**Duração:** X horas Y minutos
**Severidade:** P1/P2/P3/P4
**Time Envolvido:** @pessoa1, @pessoa2
### Timeline (SEMPRE EM UTC)
> Use UTC para evitar confusão entre timezones de servidores,
> clouds e membros do time em locais diferentes.
- 14:00 UTC - Primeiro alerta disparado
- 14:05 UTC - Engenheiro de plantão acionado
- 14:23 UTC - Causa raiz identificada
- 14:45 UTC - Mitigação aplicada
- 15:00 UTC - Sistema estabilizado
- 15:30 UTC - Incidente encerrado
### Impacto
- X% dos usuários afetados
- Y requests falharam
- Z reais de receita impactada (se aplicável)
### Causa Raiz
[Descrição técnica detalhada]
### O que funcionou
- Item 1
- Item 2
### O que não funcionou
- Item 1
- Item 2
### lições aprendidas
- Item 1
- Item 2
### Action items
| Ação | Responsável | Prazo | Status |
|------|-------------|-------|--------|
| Implementar alerta X | @pessoa | YYYY-MM-DD | TODO |
| Documentar processo Y | @pessoa | YYYY-MM-DD | TODO |
### Prevenção
Como garantimos que isso não acontece de novo?A Regra de ouro do postmortem
Blameless, não clueless.
O objetivo não é achar culpados. É achar o sistema que permitiu o erro.
Se uma pessoa conseguiu derrubar produção com um comando errado, a pergunta não é “por que ela fez isso?”, é “por que o sistema permitiu?”
Conclusão: O mindset de failure-first
Da próxima vez que você for desenhar arquitetura:
- Pega o diagrama bonito
- Circula cada componente
- Pergunta: “quando isso quebrar, o que acontece?”
Se a resposta for “não sei”…
…você acabou de encontrar seu próximo incidente.
A diferença entre sistemas que “deveriam funcionar” e sistemas que “funcionam em produção” não está na tecnologia escolhida. Está nas perguntas que você faz, e responde, antes de escrever código.
Happy path é fácil. Qualquer um desenha.
Failure path é o que separa sistemas que sobrevivem de sistemas que te acordam às 3h da manhã.
Repositório
Todos os scripts e templates desse artigo estão disponíveis no GitHub: failure-first-design

Comentários
Comentários fechados para visitantes. Entre ou registre-se para comentar.
Uma resposta para “Pare de desenhar arquitetura. Comece a desenhar falhas”
Excelente post mano, esses assuntos que separam os “meninos dos homens” hehehe…